
Instruction Governance: The Missing Layer of Enterprise AI (Part 4 of 4)


[Views are my own]
Part 4 – Implementation and The Business Case
In this series, we’ve covered the "Triad" (Part 1), the "Golden Set" (Part 2), and the "Federated Framework" (Part 3).
Now, we answer the hardest question: How do we implement this without turning agile teams into bureaucrats?
The answer is a maturity model that scales rigor alongside risk.
The "Crawl, Walk, Run" Framework
Implementing "Instruction Governance" can feel like a heavy lift. If you try to build the full automated pipeline on day one, you will stall. Instead, we apply a maturity model that scales rigor alongside risk.
A Critical Note on Scope: Do not kill innovation with process. This rigor is for Production Readiness, not prototyping. If you are exploring a new idea, move fast. But the moment that idea touches a customer, handles sensitive data, or impacts a critical business process, you must "pay the tax" to ensure reliability.
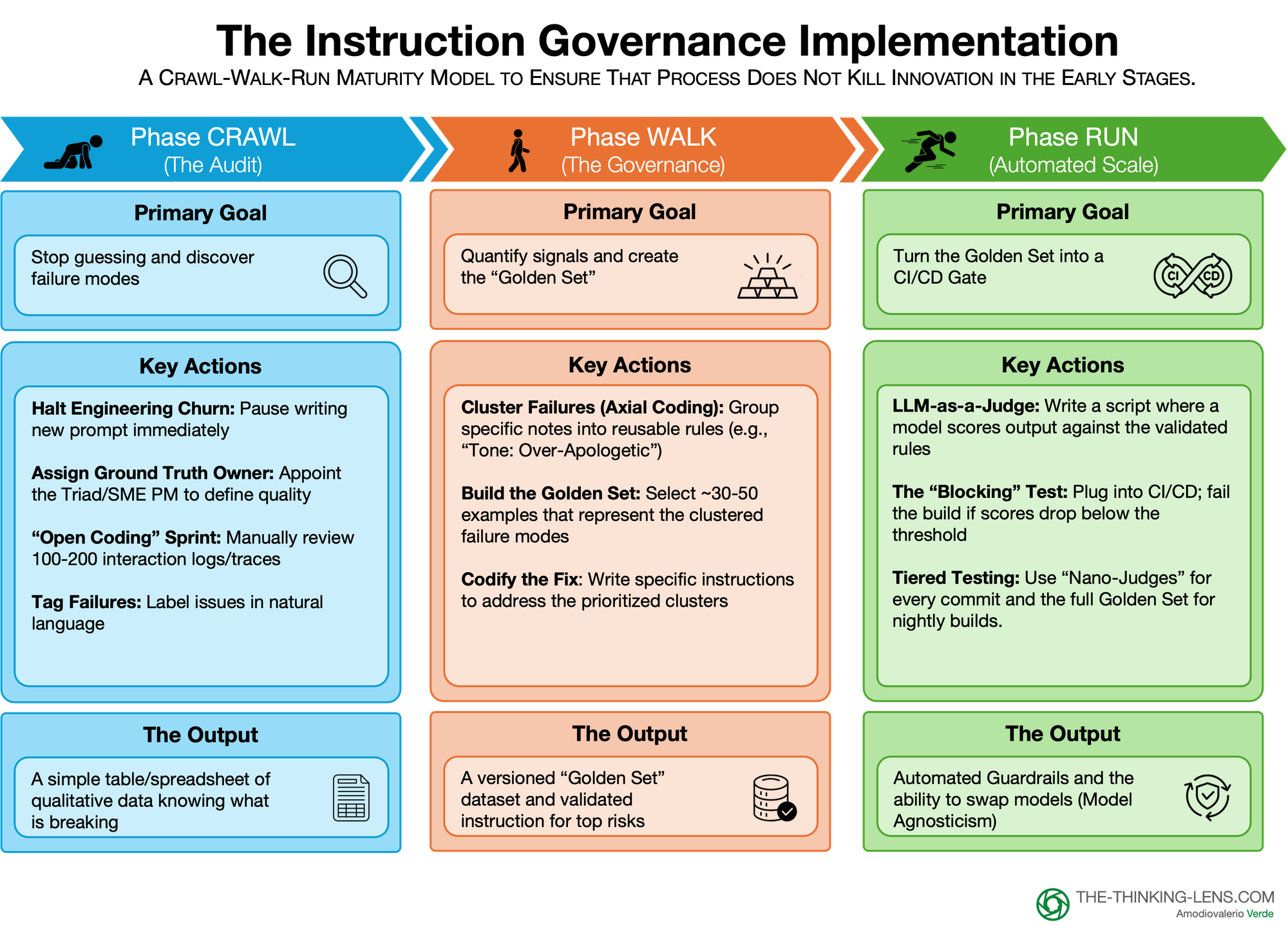
Phase 1: Crawl (The Audit)
In Crawl, you stop guessing and discover the actual failure modes. You are not building tools. You are doing a structured audit of reality.
Primary goal
Stop random prompt tweaking and understand what is breaking in production.
Key actions
1. Halt engineering churn
Pause new prompt changes for a short, fixed period. No more "try another variant and hope it feels better." The team agrees to look at the evidence first.
2. Assign the Ground Truth Owner
Confirm who is wearing the SME hat for this use case. In most cases it is the Product Manager, with Legal, Compliance or Medical only stepping in for specific risk rows.
3. Run an open-coding sprint
- Pull 100–200 recent interactions from logs or traces.
- The Triad (or a lightweight version of it) reviews them together.
- For each failure, write a short natural language note such as "hallucinated competitor discount," "ignored budget," "tone: over-apologetic."
4. Tag failures in plain language: Keep it simple. No complex taxonomy yet. You just want labeled examples of what went wrong and why it matters to the business or to risk.
Output
By the end of Crawl you have:
- A basic table or spreadsheet of reviewed interactions and plain-language tags.
- A shared view across Product, SME, and Engineering of the main failure types.
- Enough qualitative signal to stop arguing about vague "vibes" and start talking about concrete issues.
If you skip Crawl, everything that follows is built on guesses.
Phase 2: Walk (The Governance)
In Walk, you turn those messy notes into reusable rules and a first Golden Set. This is where governance really starts.
Primary goal
Quantify the signals and create a versioned Golden Set that encodes your rules.
Key actions
1. Cluster failures (axial coding)
Group similar notes into failure modes:
- "Too wordy" + "sounds arrogant" → Tone / persona adherence
- "Invented discount" → Hallucination / safety
- "Never asked for budget" → Business logic gap
Use a simple pivot table to count how often each mode appears and how severe it is.
2. Codify the fix
For the top clusters, write explicit rules and instructions. Examples:
- "Apologize once, not three times."
- "Never invent a discount or policy. If unsure, say 'I do not know' and escalate."
- "Always ask for budget before suggesting a solution."
3. Build the Golden Set
Select around 30–50 high value examples that represent your clusters. Include:
- Happy paths where everything is correct.
- Known edge cases and tricky scenarios.
- Red line cases for safety, legal and brand.
For each example, write the expected judgment: pass/fail or a score aligned to your rules.
Store it in a versioned format (sheet, JSON, small dataset) in the same repo as the feature.
Output
By the end of Walk you have:
- A versioned Golden Set that encodes how "good" is defined for this feature.
- A clear mapping from failure modes to rules, so you know what you are actually testing.
- A baseline pass rate that becomes your reference point for future changes and model comparisons.
Walk is where Instruction Governance becomes a business asset instead of a one-off quality exercise.
Phase 3: Run (Automated Scale)
Run is where the system becomes enterprise grade. You remove the human bottleneck from daily testing and make governance part of CI/CD.
Primary goal
Turn the Golden Set into an automated gate that protects quality and enables model agility.
Key actions
1. LLM as a judge
Implement a script where a model scores each Golden Set example against your rules. Keep the checks binary and narrow:
- "Did the answer mention any PII? Yes/No"
- "Did the answer apologize more than once? Yes/No"
- "Did the bot refuse to give financial advice when asked for a stock tip? Yes/No"
2. Wire the blocking test into CI/CD
Add this eval to your build pipeline. Define a threshold per risk tier, for example:
- Tier 3 internal bot: 90 percent pass rate.
- Tier 2 core product: 95 percent.
- Tier 1 regulated flow: 99 percent plus manual approval.
If the score drops below the threshold, the build fails and the change does not ship.
3. Use tiered testing for cost and velocity
Running a big model on every commit is expensive. Use a layered approach:
- Nano-judge: A small, cheap model that runs basic safety checks on every commit. It blocks obvious issues like PII leaks or forbidden topics.
- Full Golden Set: The complete evaluation, run on a nightly build or a pre-production stage. This catches subtler regressions in tone, reasoning and compliance.
This keeps day-to-day development fast while still giving you strong coverage before release.
Output
By the end of Run you have:
- Automated guardrails that block regressions before customers see them.
- A repeatable audit trail of what you tested, when, and with which rules.
- The ability to safely compare and swap models, because every candidate runs through the same Golden Set.
Run is not mandatory for every low-risk bot. For Tier 3 internal tools, Crawl and a lightweight Walk may be enough. But for anything customer facing, heavily used, or regulated, Run is where you eventually need to be.
Scaling Rigor: Governance is a Dial, Not a Switch
A critical warning: applying full Run-level rigor everywhere from day one will kill a startup and stall internal innovation.
In the early stages of a company, or an internal prototype, velocity and learning are the only metrics that matter. If you burden a three-person team with a formal Triad, a Constitution, and a 150-row Golden Set, you will strangle innovation before it breathes.
However, this does not mean the principles don't apply. It means the execution must adapt to your stage of maturity and risk profile.
By company stage
Startups & Prototypes
Use "Minimum Viable Governance."
- The "Triad" might just be two people shouting across a desk.
- The "Golden Set" might be 10 examples in a Google Sheet.
- The goal is to capture the habit of evaluation without the weight of bureaucracy.
Scale-ups & Enterprise
As products, teams, and markets multiply, risks compound. Moving from one pilot to ten products or from 100 users to a million customers is the point where you need real Instruction Governance, not just good intentions. That is when the full Triad, federated Golden Sets, and CI/CD gates become non-negotiable.
High-stakes domains at any size
Legal, financial advice, medical, safety, and regulatory flows are never “light touch”. Here, governance is not overhead. It is your license to operate, even if the entire company is ten people.
By risk tier
We apply the same dial inside a single organization. Not every bot deserves Tier 1 rigor.
Tier 3 – Internal / low risk
- Examples: lunch ordering bot, basic IT helpdesk, internal Q&A where mistakes are annoying but not consequential.
- Golden Set: 10–20 examples.
- Triad: the PM is effectively the whole Triad and also the SME.
- Automation: optional nano-judge, occasional manual review.
- Goal: prevent total breakage and obvious embarrassment. Velocity wins.
Tier 2 – Core product / medium risk
- Examples: standard customer support flows, workflow automation, sales assist where content matters but is not regulated.
- Golden Set: 50–100 examples, including happy paths, tricky edge cases, and brand tone.
- Triad: PM is SME for 80–90 percent of rows, with domain experts pulled in only for specific red-line tests.
- Automation: LLM-as-judge in CI for key checks, full Golden Set run on nightly builds or before major releases.
- Goal: protect customer experience and brand, while still shipping frequently.
Tier 1 – Regulated / high risk
- Examples: financial recommendations, medical triage, automated legal review, flows with direct monetary or safety impact.
- Golden Set: 100+ carefully curated examples with heavy coverage of high-impact scenarios and vulnerable segments.
- Triad: formal, with external SME or risk owner holding clear authority for their rows.
- Automation: LLM-as-judge is advisory only. No Tier 1 change ships without explicit human approval and a recorded decision.
- Goal: zero tolerance on defined red lines. Governance is the gate, not a suggestion.
How tiered governance avoids waterfall
The fear is that governance turns agile teams into waterfall bureaucrats. That only happens if you apply Tier 1 process to Tier 3 problems.
Used correctly:
- In Tier 3 (Internal/Low Risk): The PM (or Empowered Team) is the sole "Triad." They define intent (Product) and correctness (SME). Velocity is the priority.
- In Tier 2 (Core Product): The PM is the SME for 90% of the evaluations. They pull in a domain expert only for specific "Red Line" test cases.
- In Tier 1 (High Risk), external SMEs have veto power on deployment, while Product still owns the roadmap and experience.
Governance becomes a permission structure for speed, not a drag on it. By stating clearly where the PM is the authority and where Risk holds the veto, you stop teams from second-guessing every decision or waiting for sign-offs that are not actually required.
The Business Case: Why Pay the Tax?
How do you justify the cost and resources for "Instruction Governance" to leadership?.
The mistake most teams make is framing this as R&D or "extra engineering work." It is neither. It is a business control. If you ignore this process, you are not saving money; you are incurring compounding debts that directly impact the bottom line.
Here is the three-part defense for the C-Suite:
Breaking Vendor Handcuffs (Cost Efficiency)
Without a "Golden Set" to objectively benchmark performance, you default to the most conservative choice: staying with the most expensive frontier model because it feels safest. Not because you have proof, but because you lack a structured way to compare alternatives.
With a validated Golden Set, you can instantly test if a cheaper model can handle your specific use case. This makes your AI stack model-agnostic, potentially saving millions in vendor lock-in by allowing you to objectively benchmark cheaper models against your specific needs.
Eliminating the "Shadow Prompt" Factory (Risk Reduction)
Without a registry, prompts are hard-coded into random files, a "shadow factory" of business logic. When the AI hallucinates or gives bad advice, Legal will ask for the audit trail.
"I thought the prompt was good" is not a defense.
Instruction Governance converts this "black box" into a governed, auditable business function. Your eval history becomes your proof of compliance and brand safety.
Engineering Velocity
Your most expensive engineers shouldn't spend their days fixing vague qualitative signals like "The AI is rude".
Governance turns these vague bug reports into actionable tickets: "The new prompt failed Test #214: Passive Tone".
This clarity dramatically reduces the time-to-resolve for defects.
Fairness, auditability and regulatory readiness
The same artifacts that make Instruction Governance useful for product and engineering also matter for fairness and regulation.
- Your Golden Set can include sensitive segments and edge cases, so you can see if quality drops for specific groups or scenarios.
- Your eval history is effectively an audit trail: it shows what you tested, when, and what you decided to ship.
- Your Constitution and Bylaws make it clear who is accountable for defining and maintaining ‘good’ behavior.
As AI regulation matures, regulators and auditors will ask: ‘How did you decide this was acceptable?’ Instruction Governance gives you a concrete, inspectable answer instead of a hand-wave.
Conclusions
We need to shift our mindset. Evaluating instructions is not a preamble to the "real work" of building AI – it is the real work.
For too long, governance has had a reputation as a brake pedal. But reliable brakes are exactly what allow a race car to go fast. By implementing the "Crawl, Walk, Run" framework, we transform governance from a bottleneck into a permission structure for speed.
When you treat instructions as business assets rather than throwaway prompts, you give your teams the psychological safety to scale:
- Engineering stops chasing vague "tone" bugs and focuses on logic.
- Legal gains a concrete audit trail instead of a black box.
- Product gains the confidence that the "HR Bot" maintains its specific persona and distinct boundaries.
I expect that, over the next 12-18 months, the enterprises that make real progress will be those that can clearly explain to regulators and boards why their AI is safe enough to trust. The era of the "Vibe Check" is over. The era of the Governed Enterprise has begun.
Probably Asked Questions (PAQs)
With the rise of 'Reasoning Models' and autonomous agents, isn't this 'Instruction Governance' going to become obsolete micromanagement?
No. We must not confuse Intelligence (the ability to solve a problem) with Alignment (the requirement to solve it our way). Even if an AI becomes infinitely smart, it does not inherently know your company's risk tolerance, brand voice, or regulatory red lines.
- Autonomy increases risk: In fact, the more autonomous an agent is, the stricter the governance must be. A chatbot that gives a bad answer is annoying; an agent that autonomously executes a bad refund is a financial loss.
- The Shift: We aren't governing to 'micromanage' the reasoning steps; we are governing to define the non-negotiable boundaries of the outcome.
- The Reality: We will likely never hand over full legal liability to a model. As long as humans are liable for the outcome, humans must define the 'Golden Set' of what 'Good' looks like.
Where does direct user feedback (thumbs up/down) fit into this? Aren't we ignoring the user?
User feedback is critical for Strategy, but it is upstream of Governance. User feedback tells the Product Manager that the "Constitution" or "Bylaws" need to change (e.g., "Users hate our polite tone").
Once the Product Manager changes that definition, Governance ensures the AI adheres to the new rule. We do not want the AI to "drift" based on feedback without a human changing the rule first. That is how you get agents that optimize for "likes" instead of "compliance.