
Instruction Governance: The Missing Layer of Enterprise AI (Part 1 of 4)


[Views are my own]
PART 1 - Stop Blaming the Model – Start Evaluating Your Instructions
The Debate: Engineering Rigor vs. Enterprise Reality
This article was born from a recent discussion with peers, fellow VPs and Product leaders, on how to best approach AI evaluation. The prevailing view was that we should rely on established engineering methods: start simple, use "eval-driven development," and focus on technical accuracy.
I don't disagree. In fact, I recently watched a fantastic breakdown of AI evaluations ("AI Evals") by Hamel Husain and Shreya Shankar. If you are building AI, their engineering methodology (specifically moving from "vibe checks" to data-driven debugging) is the gold standard.
But as I considered how to apply their rigor in a complex corporate environment, I realized a piece was missing. While their approach is perfect for agile startups and scaleups, an enterprise cannot rely on a single person to define quality.
To make this work at scale, we need to wrap their engineering mechanics in a Governance Layer. We aren't rejecting the engineering approach; we are evolving it for production.
The Core Problem: We Forgot to Evaluate the Question
We are obsessed with measuring the "goodness" of AI. Teams are rushing to build complex evaluation frameworks to score AI outputs for accuracy and helpfulness. But in this rush, we have skipped the most critical step: We are so focused on evaluating the AI's answer that we have forgotten to evaluate our question.
The problem is that we often view "hallucinations" or "bad answers" strictly as technical failures. In reality, this is often a communication failure.
As humans, we are accustomed to "lossy" communication. We assume the other party understands what we mean, relying on years of shared context and professional norms to bridge the gap. When we strip away that shared human context and speak to a model, ambiguity in our language becomes a critical failure in the system.
If our instructions are flawed, our evaluations are meaningless. We aren't measuring the AI's capability; we are measuring its ability to read our minds and guess what we really meant.
Before we can apply "standard" evaluation, we must first validate our instructions. We must ensure that the rules we've codified (the prompts, the rubrics, the system messages) are clear, unambiguous, and perfectly capture our intent.
The "Compound Interest" of Failure: Why Agents Die on Vague Instructions
This need for instruction fidelity becomes existential when we move from Chatbots to Agentic AI.
In a simple chatbot, a 1% misunderstanding rate is an annoyance. But Agents operate in loops: planning, reasoning, executing, and verifying. If your instruction has a 1% margin of error, that error compounds with every step the Agent takes. At 95% accuracy per step, by step 10, the system collapses to a 60% success rate.
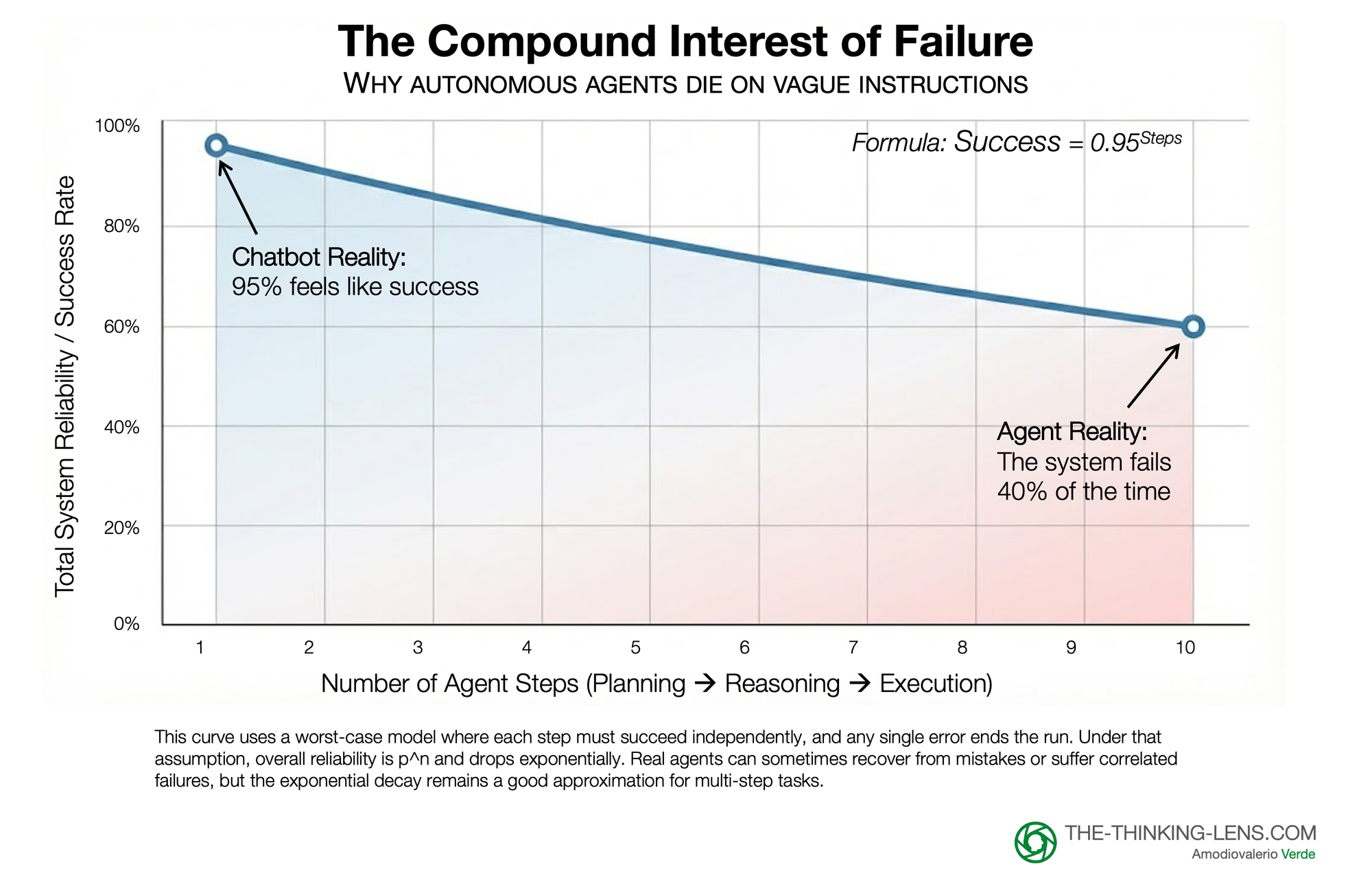
You cannot build autonomous agents on 'vibes'; the compounding math of ambiguity will break them before they launch.
The "Garbage In, Garbage Out" of AI Evals
In data science, "Garbage In, Garbage Out" refers to a simple truth: flawed input data will always produce flawed output. In this AI-era, this principle has a new, vital application: Instructions are the new data.
Consider this common (and flawed) workflow:
- Idea: "I need the AI to be a helpful, Socratic tutor."
- Codify Rule: A product manager writes a 500-word prompt defining this persona.
- Test: They give the prompt to the AI, ask a question, and get a mediocre response.
- Flawed Conclusion: "This AI model isn't good enough at being a Socratic tutor."
The real problem is that the "codified rule" was likely a first-draft hypothesis, not a validated instruction. The model may be perfectly capable, but the prompt was vague, self-contradictory, or missed crucial edge cases.
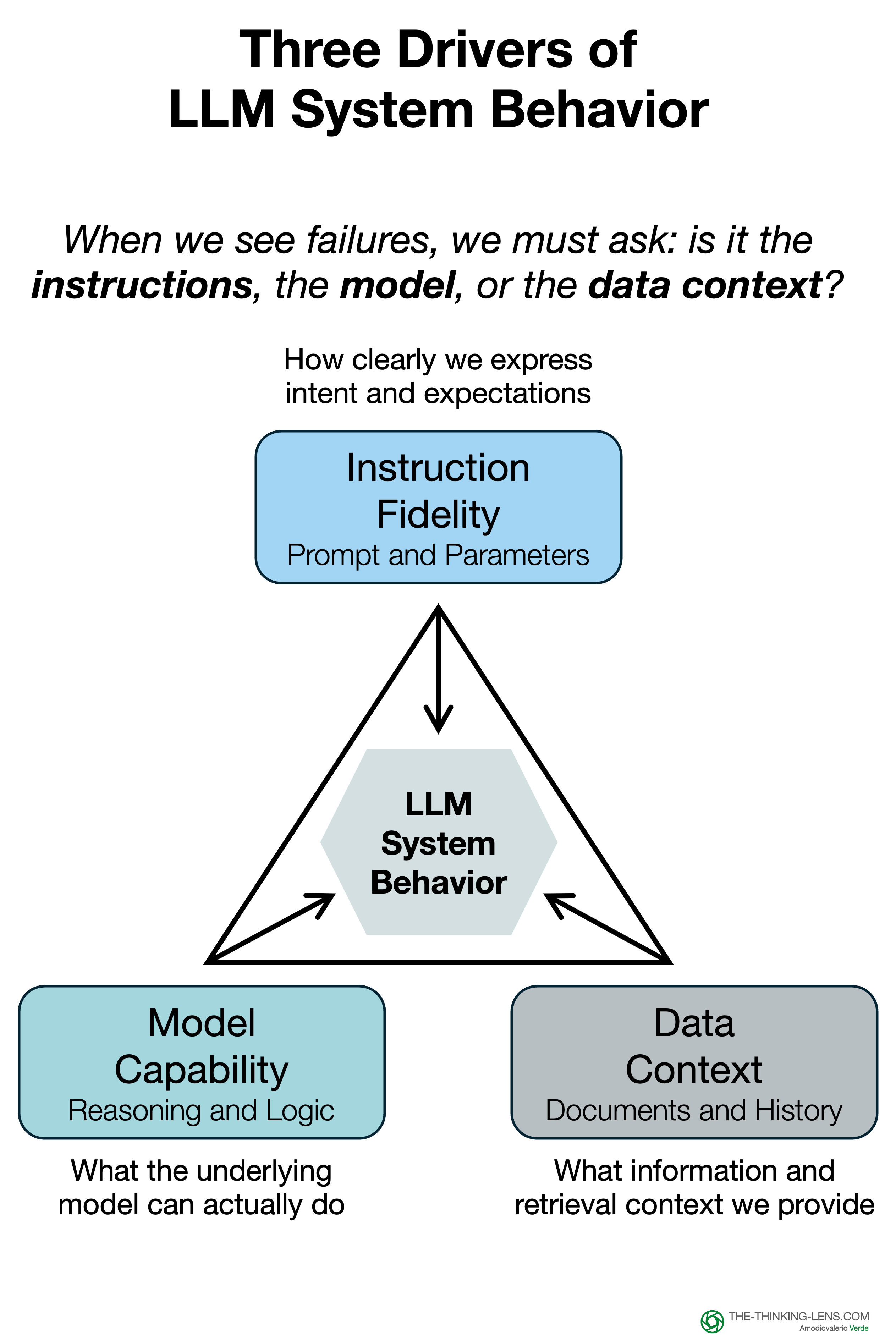
This reveals two separate problems that are too often combined:
- Instruction Fidelity: Does my prompt/rule accurately and clearly represent my intent?
- Model Capability: Can the AI execute on a perfectly clear instruction?
There is then a third variable, the Data Context
In an enterprise setting, "Instructions" are rarely just the prompt, they are the prompt plus the data retrieved from your knowledge base (RAG). If your retrieval system pulls outdated or irrelevant documents, even a perfect instruction will fail.
When you find a failure in your "Open Coding" phase, you must tag whether the culprit was the Instruction (the rule) or the Context (the retrieved data). Bad retrieval is just another form of bad instruction.
A Better Way: Discovering Rules vs. Inventing Them
We often assume we know what we want the AI to do. In reality, our initial prompts are just guesses. To move from a hypothesis to a validated instruction, we apply a rigorous three-step engineering process.
Here is how we apply that engineering rigor to business intent.
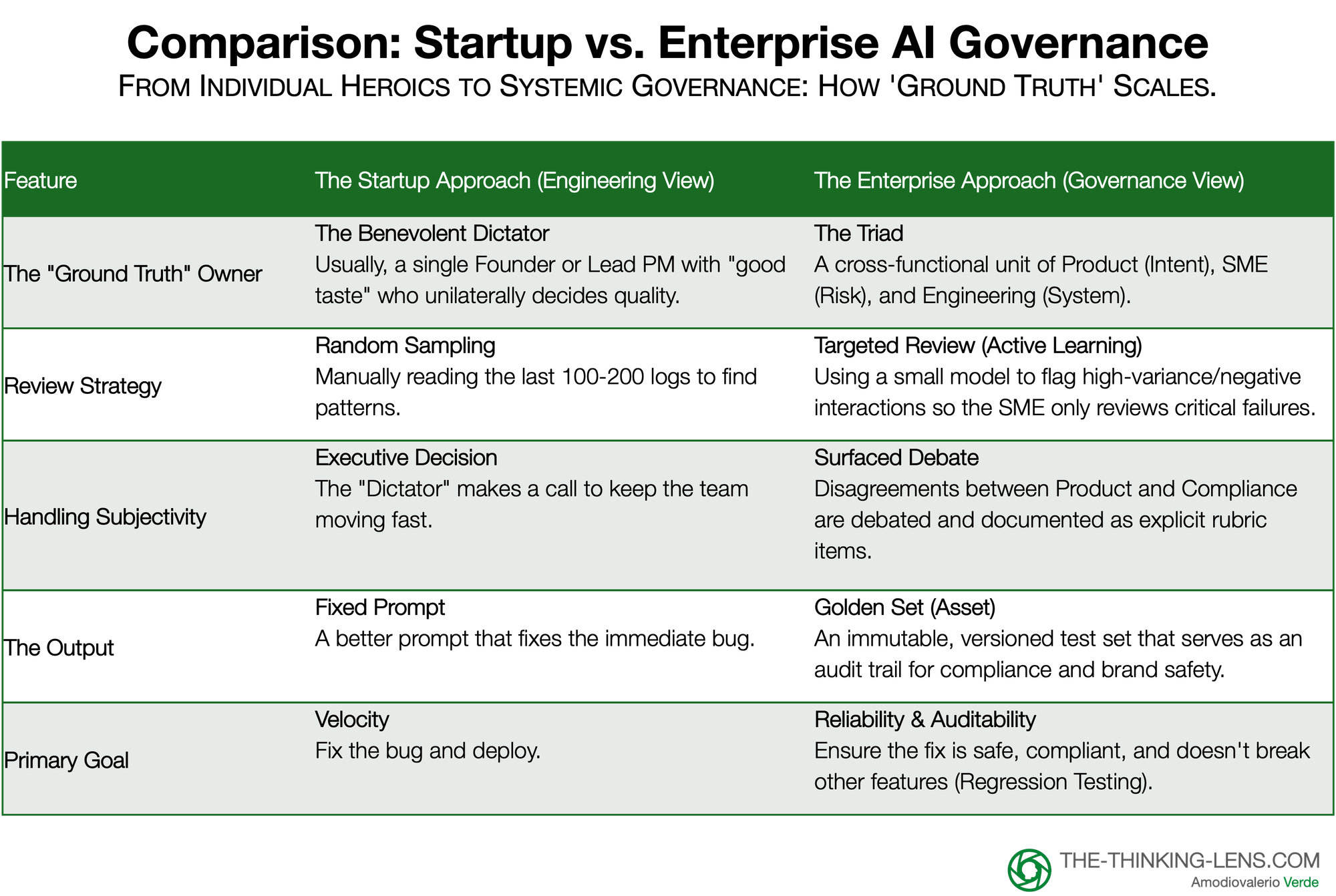
The "Who" – From Benevolent Dictator to the Governance Triad
The Standard Approach (Startup/Scaleup): In their breakdown, Husain and Shankar argue for a "Benevolent Dictator". In a startup environment, this is ideal: you appoint one person with "good taste" (usually a founder or Lead PM) to review logs, perform "Open Coding", and unilaterally decide what "good" looks like. Speed is the priority, and design-by-committee is the enemy.
The Enterprise Reality: In a large organization, the "Benevolent Dictator" does not exist. No single person holds the full context required to evaluate an AI output.
- A Product Manager knows the user intent but cannot legally validate a financial disclaimer.
- A Compliance Officer knows the risk but doesn't understand the user journey.
- An Engineer knows why the model failed but lacks the domain expertise to know if it matters.
The Solution: The Governance Triad To scale "Open Coding" in an enterprise, we replace the individual hero with a functional Triad. This is not a committee that votes; it is a cross-functional unit where each leg owns a specific aspect of "Truth."
- Product (The Intent Owner): Defines the business goal. ("Did we solve the user's problem?")
- Domain Experts/SMEs (The Risk Owner): Defines correctness and safety. ("Is this legal? Is this on-brand? Is this medically accurate?")
- Engineering (The System Owner): Owns the feasibility. ("Can we automate this test? Is this a retrieval failure or a reasoning failure?")
A Critical Distinction: Product Knowledge vs. Specialized Authority
A common question arises here: "Can't the Product Manager be the SME?"
In many cases, like a general consumer app, the answer is yes. The PM often holds enough domain knowledge to judge quality.
However, in the enterprise, we must distinguish between Product Knowledge and Specialized Authority. While a PM understands the user journey and the product's "happy path," they rarely hold the license or deep technical expertise required for adjacent high-stakes topics.
The "SME" role in the Triad is specifically designed to bring in that adjacent expertise – the Legal Counsel, the Medical Director, or the Financial Compliance Officer. The PM defines if the answer is helpful; the SME defines if the answer is allowed. In regulated industries, these are two very different questions.
How to Execute "Open Coding" with the Triad
You cannot ask a senior lawyer to read 500 raw JSON logs. To adapt the engineering workflow for the Triad, use Active Learning and Shadowing:
- Don't review random samples. Use a small model to flag interactions with high "uncertainty" or "negative sentiment".
- The "Critique Shadowing" Session: Have the PM sit with the SME for 30 minutes. Show them the 20 most critical flagged failures. Ask: "How would you have answered this?" Record their verbal reasoning.
That transcript becomes your "Open Code." This allows you to extract the "Ground Truth" from the expert without forcing them to become a data labeler.
However, simply asking for time isn't enough. You must align incentives. Frame this participation not as 'helping engineering,' but as 'automating risk oversight.' If an SME spends 30 minutes defining the 'Red Lines' now, they save 30 hours of compliance cleanup later. This 'WIIFM' (What's In It For Me) is the only way to sustain engagement in the enterprise.
Where this leaves us
Step 1 gives us something most organizations never explicitly define: a clear owner of “truth” and a repeatable way to extract it from real interactions. The Triad, the shadowing sessions, and the open coding work create a shared understanding of what “good” actually means for your AI in production. Without a clear owner of “truth”, any evaluation you run is just opinion wrapped in metrics.
At this point, though, we are still dealing with qualitative signals: anecdotes, examples, and patterns spotted by experts. That is enough to stop guessing, but not enough to make hard trade-offs, compare models, or wire this into CI/CD.
In the next step, we turn those raw observations into structured failure modes and hard numbers. We cluster the “vibes” into categories the business can reason about, decide what is “good enough to ship,” and lay the foundation for a reusable Golden Set that becomes your unit test for instructions and models.
In Part 2, I'll show how to turn these 'vibes' and qualitative notes into hard metrics and a reusable Golden Set that becomes your unit test for prompts.
Probably Asked Questions (PAQs)
Isn't this “Governance Triad” overkill for a startup or a small feature team?
For very small teams, you can absolutely start with a lightweight version of this (one person wearing multiple hats). The full, formal Triad and heavier process are for scale-ups and enterprises; I outline how to dial the rigor up and down by stage and risk tier in Part 3 (“Scaling Rigor: Governance is a Dial, Not a Switch”).
Who exactly should sit in the Governance Triad in my company?
The pattern is consistent: Product owns intent, SMEs own risk and correctness, and Engineering owns the system and automation. In Part 3 (“Pillar 1: The People – The Triad”) I go deeper on how to map those roles to real functions like Legal, Compliance, Brand, and platform engineering in a large organization.
This “open coding” with SMEs sounds slow. How do I make it practical?
You don't ask lawyers or doctors to label thousands of logs; you run short, targeted sessions on the highest-risk failures, then automate from there. In Part 2 I show how those qualitative notes become clustered failure modes and a “Golden Set,” and in Part 3 I explain how to use sprints and sampling so the manual work doesn't become a permanent bottleneck.
How do I turn these qualitative 'vibes' into real metrics and tests my stakeholders will trust?
The short answer is: cluster the failures, quantify them, and codify them into a reusable Golden Set with automated checks. That full workflow, from pivot-table view for stakeholders to “LLM-as-judge” in CI/CD, is covered step-by-step in Part 2 (“Cluster and Quantify” and “Codify and Automate”).
How do I justify the time and cost of 'Instruction Governance' to senior leadership?
You position it as a control, not a science experiment: it breaks vendor lock-in, reduces regulatory and brand risk, and improves engineering velocity. I make the detailed ROI and business-case argument in Part 3 (“The Business Case: Why Pay the Tax?” and “From Governance to Business Outcomes”).