
Instruction Governance: The Missing Layer of Enterprise AI (Part 2 of 4)


[Views are my own]
Part 2 – Why We Must Evaluate Our Instructions Before We Evaluate AI
In Part 1 of this series, we diagnosed the core problem with AI evals: we often evaluate the model's answers before validating our own instructions. We also introduced Step 1: The Governance Triad – replacing the 'lone genius' prompter with a cross-functional unit of Product (Intent), SME (Risk), and Engineering (Systems).
But once you have that team in place and they have reviewed your logs (Step 1), what do you actually do with their feedback? How do you turn a spreadsheet of messy human complaints into a rigorous engineering test?
In Part 2, we cover the execution: Step 2 (Clustering) and Step 3 (The Golden Set).
Step 2: Cluster and Quantify – Turning "Vibes" into Business Metrics
The Engineering View
Husain and Shankar advocate for grouping errors to debug effectively, a process social scientists call 'Axial Coding'. You group similar errors together so you can write a prompt that fixes multiple bugs at once.
This is essentially the "Rule of Three" applied to Prompt Engineering. In software development, you don't refactor code the first time you write it (that's premature optimization). You wait until you see the same code duplicated three times.
The same applies here:
- 1 Error: A fluke. Ignore it or spot-fix it.
- 3 Similar Errors: A pattern. This is a "Cluster."
- Refactor: Now you rewrite the instruction to handle this entire class of errors.
It is an efficiency hack for the developer.
The Enterprise View (The Governance Layer)
For a business leader, this step is not about debugging; it is about Prioritization and Resource Allocation.
In a large system, you will never fix 100% of the errors. The question isn't "What is wrong?"; the question is "What is wrong enough to block the launch?"
To answer that, we must turn qualitative complaints into quantitative data.
How to Translate "Axial Coding" for Stakeholders: Think of this process like a Design Thinking workshop with sticky notes, but rigorous.
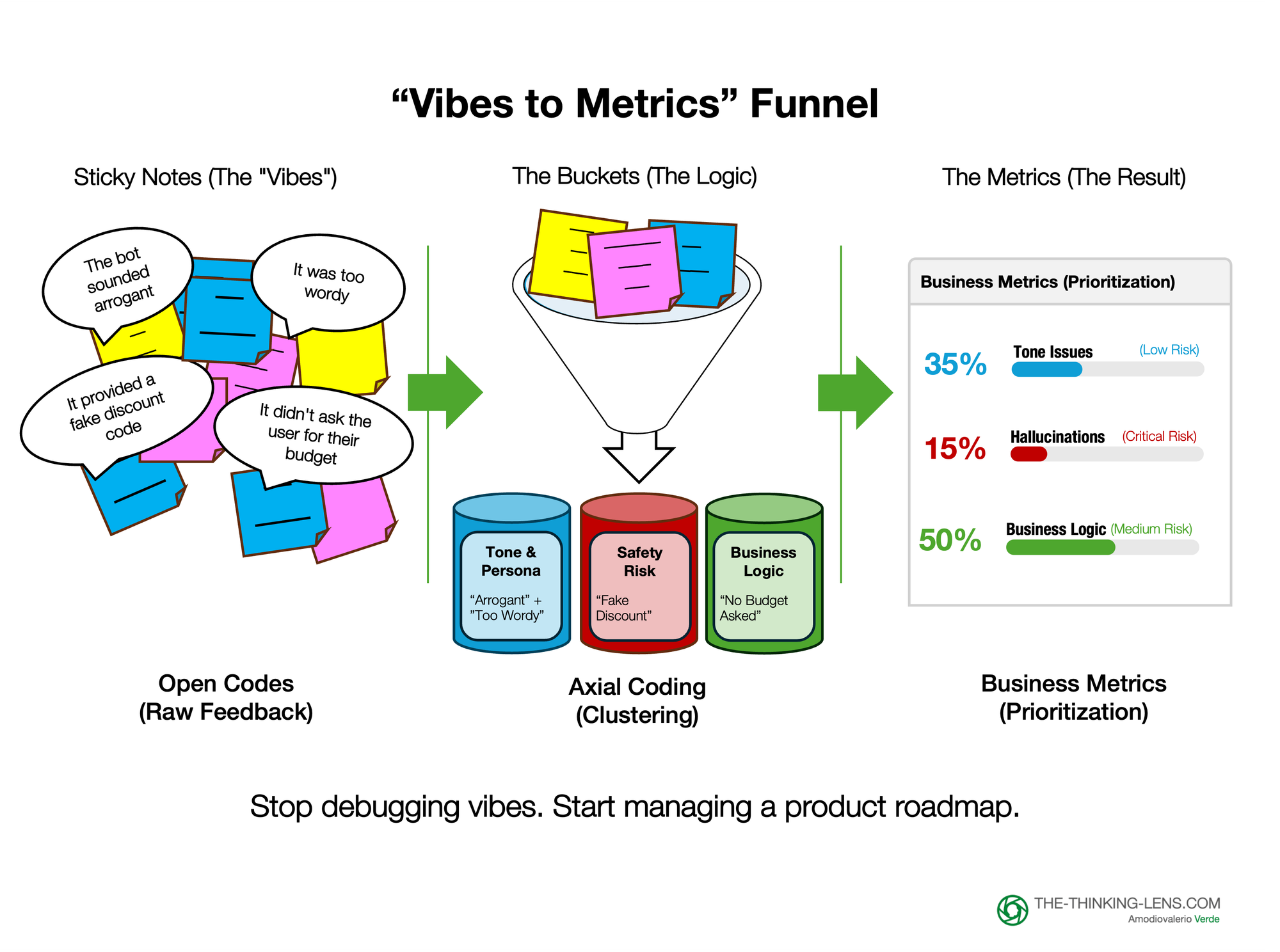
1. The Input (Open Codes): You start with the raw, messy notes from your Triad review.
- "The bot sounded arrogant."
- "It didn't ask the user for their budget."
- "It hallucinated a fake discount code."
- "It was too wordy."
2. The Clustering (Axial Coding): We group these distinct "vibes" into formal "Failure Modes."
- "Arrogant" + "Too wordy" --> Tone & Persona Adherence
- "Fake discount code" --> Hallucination / Safety Risk
- "Missed budget question" --> Business Logic Failure
Note: You can even use an LLM to do this clustering for you, asking it to categorize your open notes into these buckets.
3. The Quantification (The Pivot Table):
Now, you build a simple table. This is where the magic happens. You stop saying "The model isn't good" and start saying:
- "35% of our failures are Tone Issues (Low Risk)."
- "15% of our failures are Hallucinations (Critical Risk)." 3
The Governance Decision
This quantified view allows the Product Lead to make an educated tradeoff decision:
"We will ship with the Tone issues (and fix them in Week 2), but we cannot ship until Hallucinations are below our risk threshold (e.g., <2% for financial advice, <5% for general support)."
Without this clustering step, you are just playing "whack-a-mole" with individual bugs. With it, you are managing a product roadmap.
Step 3: Codify and Automate – The "Golden Set" as Your Unit Test
The Engineering View: Husain and Shankar advocate for "Eval-Driven Development." Once you identify a failure mode (e.g., "The AI is too verbose"), you write a test case to check for verbosity, then you tweak the prompt until it passes. The goal is Debugging: getting the model to work right now.
The Enterprise View (The Governance Layer): In the enterprise, getting it to work once isn't enough. You need to ensure it keeps working forever, regardless of model updates or prompt tweaks. The goal is Regression Testing and Auditability.
We achieve this by transforming our manual "Open Coding" findings into two permanent assets:
1. The "Golden Set" (The Contract)
Instead of throwing away your spreadsheet of reviewed logs, you curate it. You select the 50-100 interactions that best represent your "Clusters" (from Step 2).
- The Happy Path: Examples of perfect behavior.
- The Edge Cases: Tricky inputs that previously caused failures.
- The "Red Lines": Dangerous inputs (e.g., PII, competitors) that must be handled strictly.
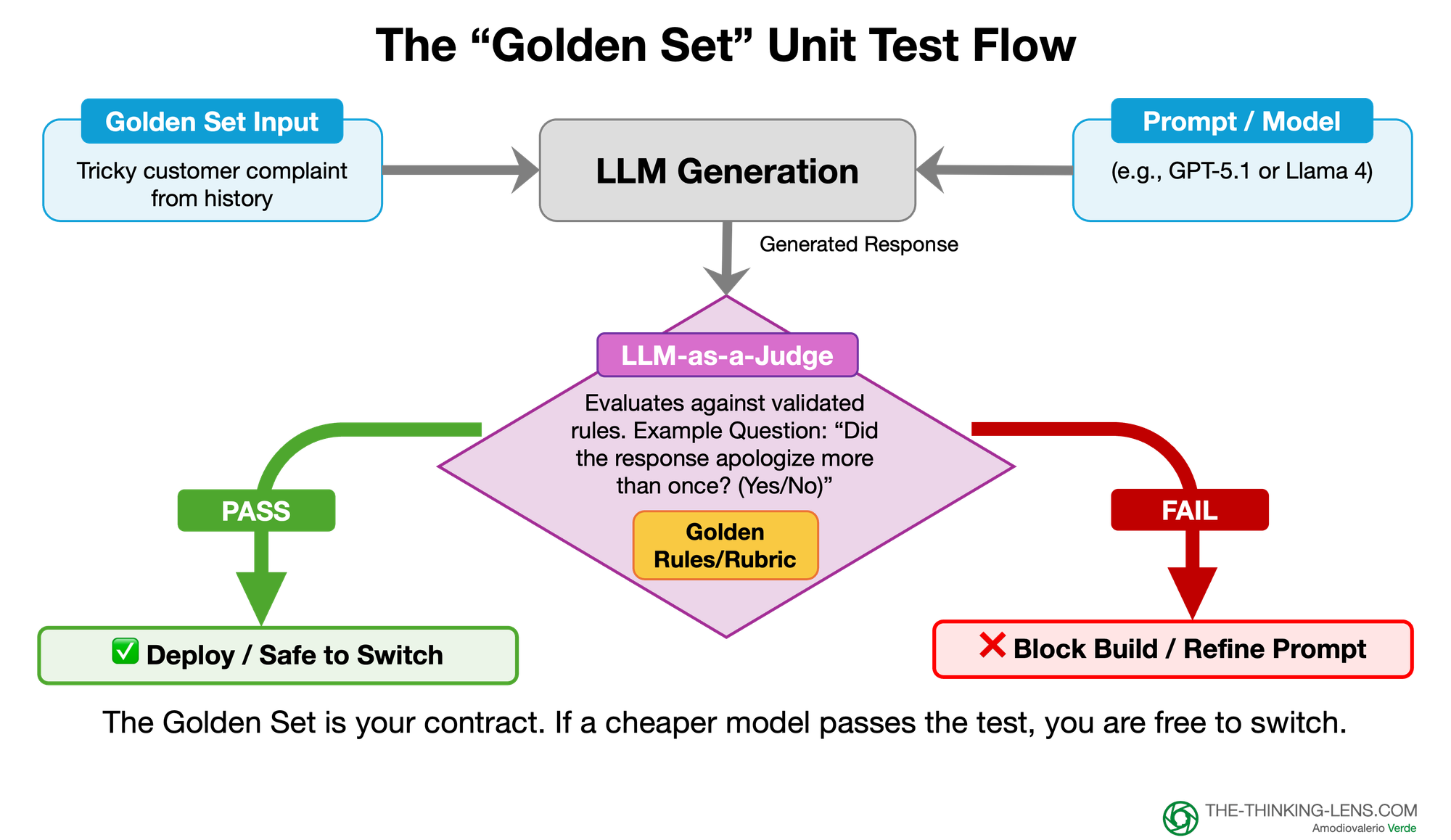
This "Golden Set" becomes the immutable "Truth" for your product. It serves as the Unit Test for your prompt logic.
We are not trying to prove statistical significance across the distribution; we are running a regression test on known failure modes.
2. The LLM-as-Judge (The Automated Auditor)
You cannot have a human re-read 100 logs every time an engineer changes a comma in the prompt. You need automation. We use an "LLM-as-Judge" to score your Golden Set. But – and this is critical – we do not ask vague questions like "Is this answer good?".
We ask binary, rule-based questions derived from your Axial Coding:
- Vague/Subjective: "Is the tone polite?" (Bad Eval)
- Binary/Governed: "Did the response apologize more than once? (Yes/No)" (Good Eval).
The Business Payoff: Breaking Vendor Lock-in This is the strongest argument for the C-Suite. Once you have a "Golden Set" and an automated "Judge," you are no longer beholden to a specific model provider.
Scenario: You are currently paying for the frontier proprietary model (e.g., GPT-5-class). You want to switch to a specialized open-source model (e.g., next-gen Llama-class open-source model) to save on costs.
- Without Governance: You are terrified to switch because you don't know if the cheaper model is "smart enough."
- With Governance: You run the cheaper model against your Golden Set. If it passes around 98% of the test cases, you have a strong signal that it is safe to consider switching.
The Golden Set gives you the confidence to objectively benchmark cheaper models against your specific use case, making informed cost-quality trade-offs. While the Golden Set validates quality, the final switch obviously requires validation of latency, security, and data privacy constraints.
A Concrete Example: The "Voice of Customer" Analyzer
To illustrate this process, let’s look at a real-world failure mode I encountered when trying to automate customer feedback analysis.
The Mission:
I needed an AI agent to scan thousands of raw NPS comments and extract "Actionable Feature Requests".
The Flawed Hypothesis (The "Vibes" Approach)
I started by writing a "perfect" prompt based on my intuition of what a feature request looks like.
- Hypothesis: "Extract any sentence where the user explicitly asks for a new feature or functionality."
- The Result? The AI failed. It missed high-value signals. It rejected a critical piece of feedback: "I have to click 'Save' five times just to close a ticket. It’s exhausting."
- Why? Because the user didn't ask for a feature. They just complained about pain. The AI followed my rule perfectly, but my rule was wrong.
The "Open Coding" Discovery (Phase 1)
Instead of randomly tweaking the prompt ("Be smarter! Find better insights!"), I acted as the Ground Truth Owner. I pulled 50 random logs where the AI returned "No Request Found" and reviewed them manually.

The Validated Instruction (Phase 2)
I analyzed the spreadsheet (Axial Coding). I realized that 40% of my missing data came from what I clustered as "Implicit Pain Points."
I rewrote the rule based on this data, not my initial guess.
- Old Rule (Vibe-based): "Find explicit requests."
- New Rule (Validated): "Classify as a 'Feature Request' if the user describes a specific friction point or workflow blocker, even if they do not explicitly suggest a solution. Pain implies a request."
The Automated Gate (Phase 3)
I didn't just trust this new prompt. I took those tricky examples (the slow dashboard, the misplaced button) and added them to my "Golden Set."
Now, I have an "LLM-as-Judge" that runs on every prompt update. It specifically checks: "Did this prompt catch the 'Slow Dashboard' complaint? (Yes/No)."
If a new model misses it, I revert and review the rule. And run the LLM-as-Judge again.
What’s Next?
We have now successfully moved from a vague hypothesis to a rigorously validated instruction. We have a "Golden Set" that acts as an immutable unit test, and an "LLM-as-Judge" that automates the review, allowing us to catch regressions instantly. For a single feature or a startup, this engineering workflow is often enough.
But how do you scale this rigor across a global enterprise with fifty distributed teams? How do you ensure the HR bot is as compliant as the Finance bot without creating a massive bureaucratic bottleneck? And crucially, how do you justify the cost of this "governance tax" to the C-Suite?
In the final installment, Part 3: Scaling AI Governance, we will move from the engineering of instructions to the management of them. We will explore Federated Governance, the financial Business Case for breaking vendor lock-in, and the practical "Crawl, Walk, Run" roadmap for implementation.
Probably Asked Questions (PAQs)
Isn’t a Golden Set of 50-100 examples too small to be reliable?
The Golden Set is not a full simulation of production; it is a unit test for your instructions. For most features, 50-100 carefully chosen examples are enough to cover your key “happy paths,” edge cases, and red lines. In high-risk domains, you simply scale the set up and add more severe scenarios. In Part 3 (“Scaling Rigor: Governance is a Dial, Not a Switch”), I show how we increase Golden Set size and strictness by risk tier, so regulated use cases get much heavier coverage.
Won’t the Golden Set go stale as user behavior and products change?
Yes, and treating it as static is a failure mode. The Golden Set is a living asset, not a museum exhibit. We regularly refresh a portion of it with recent live traffic, especially for segments where we see drift in CSAT, NPS, or failure patterns. Part 3 (“The Living Eval Set”) covers how to rotate in new examples, retire outdated ones, and avoid overfitting to yesterday’s world.
Isn’t “LLM-as-judge” risky? Aren’t we just adding another opaque model into the loop?
It is risky if you ask vague questions like “Is this good?” and blindly trust the scores. The trick is to narrow the judge to simple, binary rules derived from your axial coding, like “Did the response apologize more than once? (Yes/No).” We also treat the judge like any other component: we spot-check it with humans, and in sensitive cases we use a different model as the judge than the one under test. The goal is not perfection; it is to turn subjective complaints into consistent, auditable signals that humans can still override.
Are we at risk of “teaching to the test” and overfitting to the Golden Set?
Any test can be abused if you optimize only for the score. That’s why the Golden Set is built from real failures and edge cases, refreshed over time, and paired with live metrics like CSAT, containment, and incident rates. If the model passes 100% of the evals but your customer outcomes degrade, that is a signal that the eval set is stale, not that the world is “wrong.” In Part 3, I show how we tie eval themes directly to business KPIs to prevent this drift.
Isn’t this clustering and Golden Set work overkill for low-risk or early-stage use cases?
It would be, if you applied the full process everywhere. The point is to scale rigor with risk. For a low-stakes internal bot, your “Golden Set” might be 10 examples in a spreadsheet and a single LLM-as-judge check. For a Tier 1, regulated workflow, you need dozens of carefully curated red-line cases, formal sign-off, and CI/CD gates. Part 3 (“Crawl, Walk, Run”) lays out how to start light and dial the governance up only when the use case, user count, and regulatory exposure justify it.
Can we really make vendor decisions based on one Golden Set pass rate (e.g., 98%)?
The Golden Set gives you a first, objective filter, not the entire answer. A strong pass rate on your curated tests tells you that a cheaper model is viable for your specific failure modes and red lines. After that, you still validate latency, throughput, cost, and any domain-specific constraints before switching. The difference is that you are no longer debating “model quality” in abstract; you are comparing concrete behavior against the same, governed yardstick.
How do I make these evals meaningful to executives who only care about KPIs?
You don’t sell them on “Golden Sets” and “LLM-as-judge.” You translate eval themes into the metrics they already track: intent recognition into containment rate, factual accuracy into NPS and re-open rate, safety into compliance incidents, and tone into CSAT and brand consistency.