
Instruction Governance: The Missing Layer of Enterprise AI (Part 3 of 4)


[Views are my own]
Part 3 – The Three Pillars of AI Governance
Most enterprises are now past the “one AI pilot” phase. You have dozens of teams, dozens of models, and far more prompts than anyone can count.
Each team has its own agent, its own prompt file, its own “quality bar”. When a customer, regulator, or CISO asks, “Why did the system answer this way?”, there is no single place to point to. No shared rules, no audit trail, and no clear owner of “truth”.
That is not a platform. That is a governance risk.
In Part 1 and Part 2 of this series, I stayed at the feature level:
- We replaced the lone “prompt genius” with a Governance Triad.
- We turned messy logs into clusters and a Golden Set of examples.
- We wired that Golden Set into LLM-as-Judge so we could test instructions on every change, not once per quarter.
That flow works well for a single product team. The problem is scale.
How do you stop “fifty teams, fifty prompts” from becoming a shadow prompt factory? Who owns ground truth across products and functions? How do you dial governance up for high-risk use cases without suffocating low-risk experimentation?
This part is about that shift: from Prompt Engineering (an individual skill) to Instruction Governance (an organizational control).
Prompt engineering asks, “Can I get this model to behave?”
Instruction Governance asks, “Can our company prove, at any time, that the AI followed the rules we agreed to?”
It does not replace product discovery or data quality work. It sits on top of them. Discovery decides what good looks like. Governance enforces that the AI actually behaves that way, every time, in production.
The Three Pillars of Governance
The system I describe rests on three structural pillars:
- The People – A Triad that owns intent, risk, and systems.
- The Asset – A living Golden Set that encodes your rules.
- The Mechanism – Automated guardrails in CI/CD that turn those rules into hard gates.
Once these three are in place, you can scale AI across the enterprise without scaling chaos.
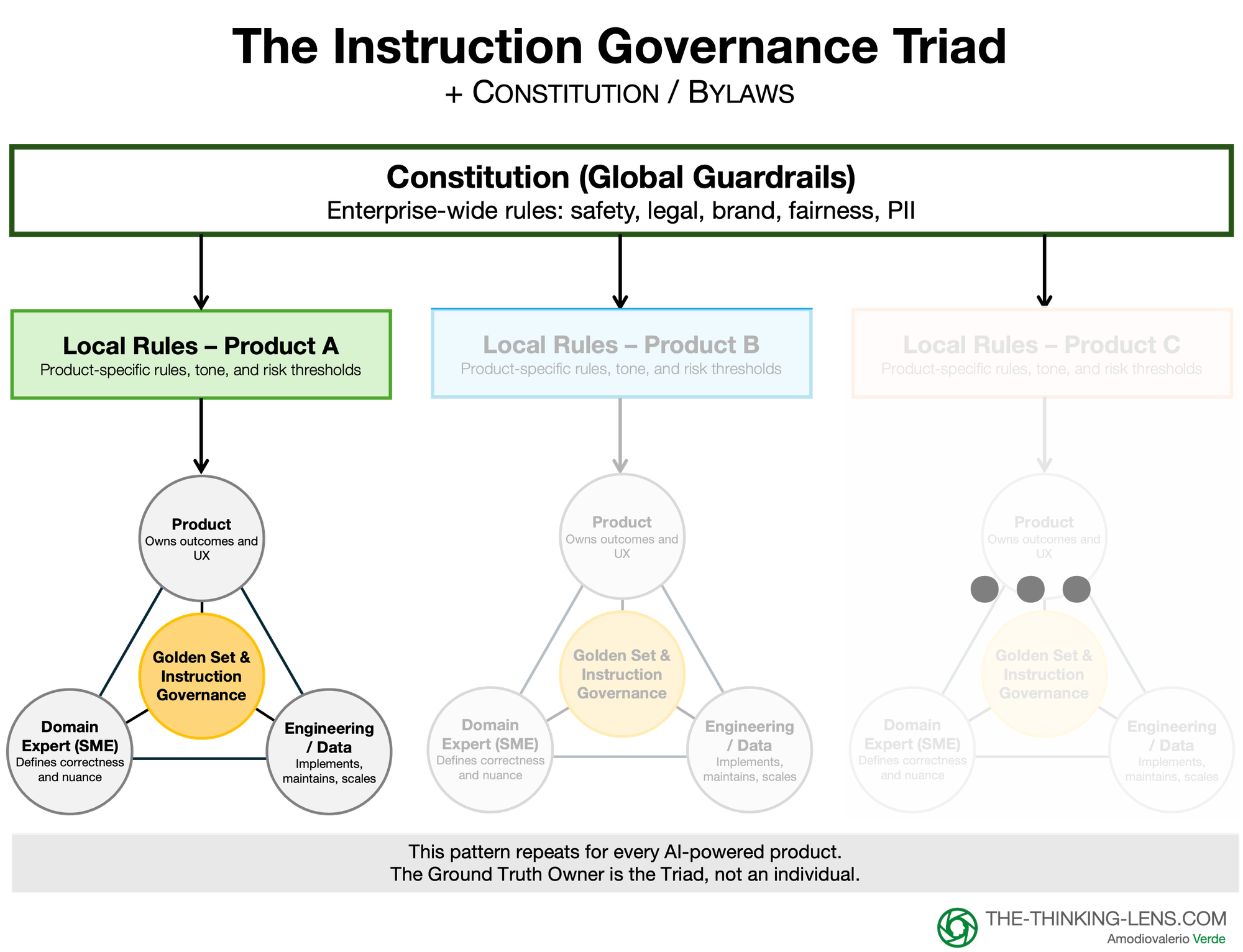
Pillar 1: The People ("The Triad")
The "Ground Truth Owner" described in Step 1 cannot be a single hero that doesn't scale. In an enterprise, this role is a function, not a person. It is a "Triad" consisting of:
- Product: Owns the business intent (What are we trying to achieve?).
- Domain Experts (SMEs): Own the content and risk (Legal, Compliance, Brand, Medical). They are the ones performing the "open coding" to validate what "good" means.
- Engineering: Owns the systems (How do we automate this test and plug it into our CI/CD pipeline?).
Crucial Note: The SME is a Hat, Not a Hire Do not mistake this for a committee. In most medium and low-risk use cases, what I’ll later call Tier 2 and Tier 3, the Product Manager is the SME.
I use a simple three-tier risk model across this series:
- Tier 1 – high-risk / regulated flows (legal, medical, safety, financial advice)
- Tier 2 – core product flows that affect customers, money, or trust
- Tier 3 – internal and low-risk tools where mistakes are annoying but not harmful
In Tier 2 and Tier 3, you are the expert on user intent, tone, and utility. You do not need a lawyer to tell you if the bot is being helpful; you only need them to tell you if it is being liable. Part 4 goes deeper into how governance rigor scales across these tiers.
For General Features: The PM wears the "SME" hat. They build the Golden Set and run the evals.
For Regulated Features: The "SME" hat is passed to Legal or Medical only for the specific rows in the Golden Set that touch those risks.
Governance allows you to move fast on the 80% safe zone, while putting hard gates only on the 20% danger zone.
The Rules of Engagement
- Handling Subjectivity: Ground truth is rarely perfectly objective. Different SMEs will disagree on what 'good' looks like. The Triad handles this not by removing subjectivity, but by surfacing it: explicitly debating the disagreement and documenting the final decision as a rubric item.
- The "Anti-Handoff" Rule: These roles must not be siloed. If Product simply "throws the intent over the wall" to Engineering, the system fails. Engineers should sit in on "open coding" sessions to build intuition, and SMEs must see the automated test results.
- The "Delegate" Protocol: Let’s be realistic: your General Counsel or Chief Medical Officer will not log into a tool to label data, and they shouldn't. In the enterprise, the "SME" role in the Triad is often a deputized delegate, while the Delegate sits in the Triad to execute the Bylaws (the day-to-day validation). This ensures the "Ground Truth" is authoritative without becoming a bottleneck.
Pillar 2: The Asset ("The Living Eval Set")
The manual review process creates your most valuable strategic asset: a human-validated "Golden Set" that serves as the ground truth for your AI. It effectively becomes the "unit test" for your prompt logic.
The Rules of Maintenance
- Avoid "Museum Exhibits" (Drift): A failure to avoid is treating the Golden Set as static. Customer intent drifts. If the model passes 100% of evals but user satisfaction drops, your set has become stale. You must regularly refresh a portion of the set with recent live traffic.
- Avoid Overfitting: If you only test yesterday’s scenarios, you overfit to yesterday’s world. A robust Golden Set must include both "happy path" scenarios and ugly edge cases.
The "Federated" Golden Set
Your Golden Set is not a monolith; it is a collection of specific rules. Different rules require different judges.
- Rows 1-40 (Utility & Tone): The PM is the SME. They judge if the bot answered the user's question correctly.
- Rows 41-50 (Compliance Red Lines): The Compliance Officer is the SME. They judge only the specific rows regarding financial disclaimers or PII.
You do not block the build waiting for Legal to review the "Tone" rows. You segment your Golden Set so the PM maintains velocity on product quality, while the external SME focuses strictly on risk.
Pillar 3: The Mechanism ("The Automated Guardrails")
A Golden Set is useless if it sits in a spreadsheet. The third pillar is the automation that enforces your rules, transforming evaluation from a "meeting" into a "system".
- It plugs into LLMOps (The CI/CD Gate): The Golden Set becomes the "unit test" for your AI. You plug this into your deployment pipeline. If an engineer changes a prompt and the "Persona Adherence" score drops below the threshold, the build fails automatically.
- It enables Model Agnosticism: With these automated guardrails, you are no longer locked into a specific model. You can swap for a cheaper one. The guardrails give you a rapid, directional signal on whether the new model is safe to ship, allowing you to optimize for cost without risking quality.
The Feedback Loop: Managing the Red Light
What happens when the test fails? In a governed system, a failed test triggers a specific protocol.
- The Alert: The pipeline blocks deployment. "Test #214 (Persona Adherence) Failed".
- The Triage: The Ground Truth Owner reviews the failure and makes one of two decisions:
- Scenario A (Regression): The model broke. Action: Engineering fixes the prompt.
- Scenario B (Evolution): The model's new answer is actually better than our old standard. Action: We update the "Golden Set" to reflect this new truth. This decision record becomes your audit trail.
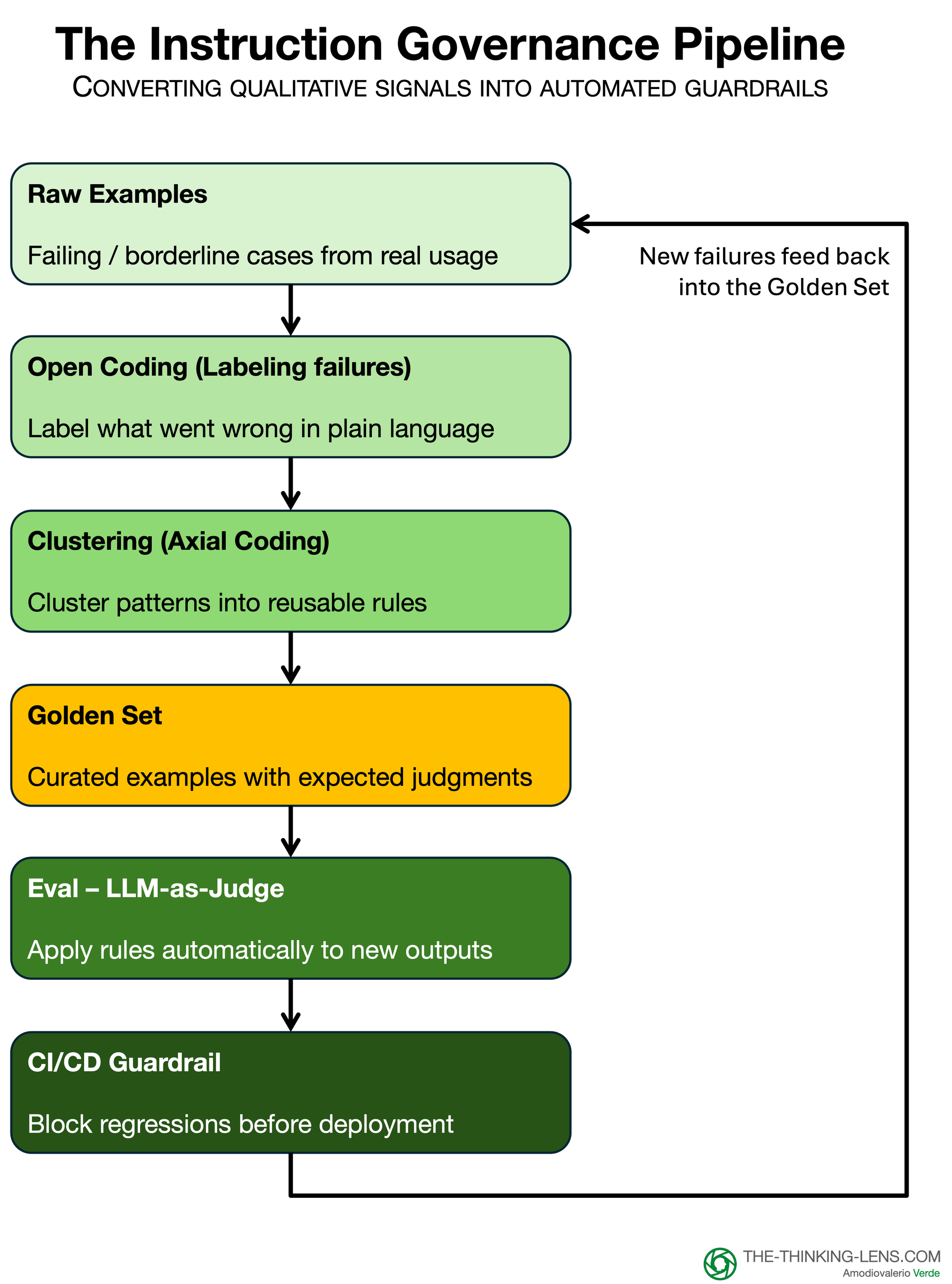
Scaling to the Enterprise: Federated Governance
In a massive organization, a single team cannot review every prompt. We must move to Federated Governance using a two-layer model:
Layer 1: The Constitution* (Global)
- Owned by: Compliance / CISO / Brand.
- Scope: Universal non-negotiables (e.g., "No PII," "No medical advice").
- Execution: Mandatory eval sets that run on every build across the company.
Layer 2: The Bylaws (Local)
- Owned by: The Product Triad (PM, SME, Eng).
- Scope: Domain-specific logic (e.g., "The HR bot must be empathetic," "The Finance bot must be terse").
- Execution: Teams own their own "Golden Sets" and are responsible for their own quality metrics.
In both layers, humans stay on the hook. The models provide fast, consistent signals, but the accountable owner for each layer signs off on what is ‘acceptable risk.’ The judge automates the checks; it does not replace judgment.
*Note: We use 'Constitution' here as a governance metaphor for global policies, distinct from specific vendor technologies like Anthropic's Constitutional AI.
The Operational Owner
This coordination – managing the Golden Sets, ensuring the Triad meets, and maintaining the audit trail – requires a specific owner.
In modern product organizations, this is the natural domain of Product Excellence/ProductOps. However, many legacy enterprises do not yet have this function.
If you lack a ProductOps team, this responsibility typically sits best with Center of Excellence (CoE), Technical Program Management (TPM), Engineering Excellence, or a dedicated Quality Guild.
The title on the business card matters less than the function: someone must ensure that the "science" of building AI doesn't get lost in the "art" of product management. Without this designated operator, the Golden Set will rot, turning your 'unit test' into a 'museum exhibit' that no longer reflects reality.
This role is also critical for managing the effort curve. Stakeholders often fear that Governance is a permanent drag on speed, but the work is front-loaded. While the initial creation of a Golden Set is labor-intensive, maintenance is merely management-by-exception.
When do you move from a loose startup culture to Federated Governance? We apply the Rule of Three again, but this time to teams instead of bugs.
- 1 Team: A Benevolent Dictator decides.
- 2 Teams: They talk to each other.
- 3 Teams: If three different teams are writing their own 'Financial Disclaimer' prompts, you have toxic duplication.
That is the trigger point. You don't write a global policy (The Constitution) for one team. You write it when the cost of not having it outweighs the effort of building it.
Note: The Rule of Three applies to optimization. In high-stakes zones like Legal or Medical, Risk overrides this rule. You don't wait for three lawsuits to build a guardrail; you build it on Day 1.
This is also where the politics show up. Some teams will see Governance as ‘extra work’ and try to route around it. The only way this sticks is if leaders make it clear that AI features without a Golden Set and a clear owner of ‘truth’ are not ‘done,’ no matter how impressive the demo looks.
It is also critical to manage the cadence of review so your Triad doesn't burn out. We utilize a Sprint vs. Sample model:
- Launch & Major Updates: The Triad runs a high-intensity 'Open Coding' sprint on 100% of a small sample set to establish the baseline.
- Maintenance: Once the Golden Set is locked, the operational owner only reviews a targeted 1% sample of live traffic to catch drift. Governance is a heavy lift at the start, but a light maintenance routine thereafter.
What’s Next?
We have the Structure (The Triad, The Constitution, The Golden Set). But how do you actually implement this next Monday without grinding your engineering team to a halt?
In the final installment, Part 4, I will share the "Crawl, Walk, Run" implementation roadmap, the Business Case for the C-Suite (ROI of Governance), and how to dial rigor based on risk so you don't kill innovation.
Probably Asked Questions (PAQs)
You advocate for a "Federated" model, but doesn't allowing local teams to write their own "Bylaws" create inconsistent brand voices?
This is where the Constitution (Layer 1) must be aggressive. While the content logic belongs to the local Bylaws (e.g., specific HR policies), the persona and tone guardrails often belong in the Constitution. If "Brand Voice" is a non-negotiable for your enterprise, it moves from a local "Bylaw" to a global "Constitutional" check that runs on every single build, regardless of which team owns the bot.
This "ProductOps" role you mention – we don't have that. Who does this work?
If you don't have ProductOps, look to your Technical Program Managers (TPMs) or your QA Leads. The title doesn't matter; the function does. Someone needs to own the process of maintaining the Golden Set, ensuring the Triad meets, and checking the audit logs. If you leave this to the individual Product Manager without support, the Golden Set will eventually rot and become a "museum exhibit" rather than a test.
Does every prompt change really need a "Governance Triad" meeting? That sounds like Waterfall.
Absolutely not. For Tier 3 (Low Risk) internal tools, the Product Manager is the Triad. They define intent, check correctness, and ship. The full formal Triad with external SMEs (Legal/Medical) is reserved for Tier 1 (High Risk) flows. Governance should be a dial, not a switch. (I cover exactly how to set these Tiers in Part 4).