
The Semantic Supply Chain: The Autonomy Ladder


Part 3 of 4: The Autonomy Ladder
[Views are my own. Not legal or compliance advice.]
This is the moment where mistakes move from low-cost errors to business-impacting failures.
Because now we're not just generating answers, we're executing workflows.
In Part 1 and Part 2, we established how to define boundaries (Capability Contract), assemble context (Retrieval), and separate plausibility from proof (Engine vs Wrapper). But that was all about generation: producing text, drafts, and explanations.
Now we're at the point where GenAI stops being "a system that produces answers" and becomes "a system that can execute a workflow."
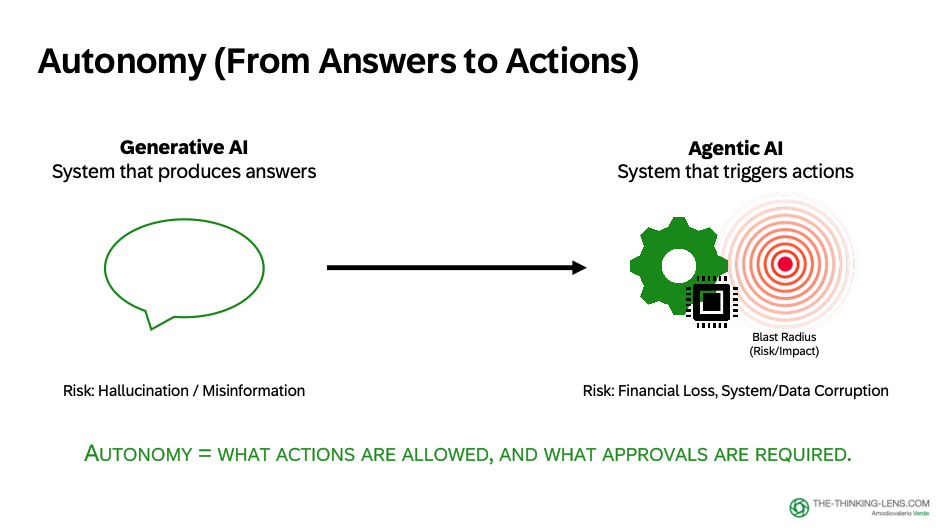
This is the shift from generation to execution. From Generative AI to Agentic AI.
And this is where Station 5 matters: Autonomy → deciding what the product can do by itself, what it can only propose, and what always needs a human signature.
What Is an Agent (In Operational Terms)?
Let's define an agent in practical, operational terms.
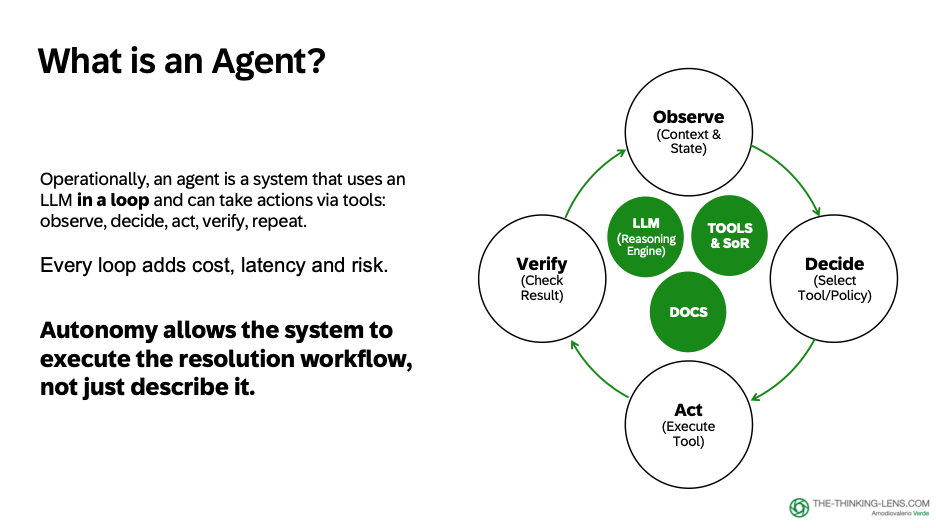
An agent is a system that, in a loop:
1. Uses an LLM to reason
2. Retrieves truth from systems of record
3. Grounds answers in documents
4. Takes actions via tools
Observe → Decide → Act → Verify → Repeat.
Each loop adds cost and latency. And as chains get longer, error rates compound because mistakes in early actions can corrupt later decisions.
When tools can write to real systems, the design must limit what can happen per loop.
Applying This to Blocked Invoice Resolution
(our running case across the series)
So far, our copilot explains. Now we want it to execute parts of the resolution workflow.
An agent loop here is natural:
Observe: Read invoice status, hold reason, PO, GR/IR, approval chain
Decide: Choose the next best step based on policy and history
Act: Create a task, request approval, draft vendor email, route to the right queue, add case notes
Verify: Read back the system of record, confirm expected state, and if not explicitly confirmed, stop and escalate
The speed gain is fewer handoffs, not human replacement. The system gathers facts, drafts the next step, and the human approves only when stakes are high and judgment is required.
The Autonomy Ladder: A Control Framework
Autonomy and agents are not binary. Each level increases potential value and potential impact unless you constrain scope, require approval, or add a cancel window.
Treat this ladder as a control framework, not a maturity sequence.
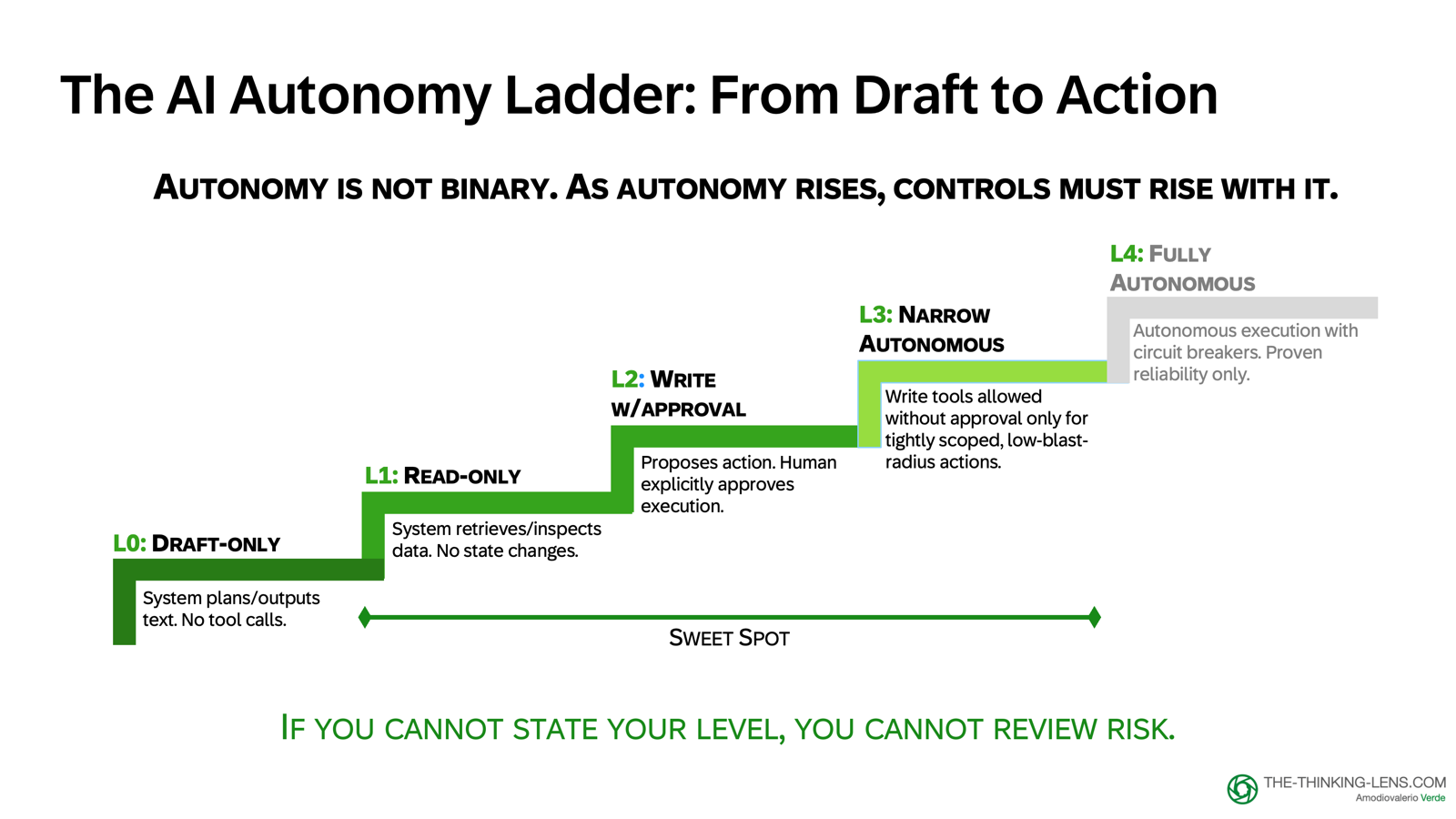
Level 4 is not the goal. In many enterprise workflows, Level 1 to 3 is the right endpoint.
Level 0: LLM-Only (Generation-Only, No Tools)
What it does: Generate text, summaries, rewrites, drafts
No access to: Systems of record, tools, external data (beyond what's in the prompt)
Acceptable for: Drafts and transformations when clearly labeled as non-authoritative like summaries, rewriting, proofreading
Not acceptable for: Enterprise decisions or claims that require correctness, traceability, or policy compliance
Control requirement: Draft labels, clear non-authoritative messaging
Example (Blocked Invoice Copilot):
"Draft an email to the supplier requesting the missing delivery note"
Level 1: Read-Only Tools
What it does: Retrieve and inspect live system state, but cannot change anything
Acceptable for: Explanations grounded in system-of-record facts, policy lookups, status summaries
Control requirement: Show timestamps, sources, field provenance
Risk: Low (no state changes, but must handle sensitive data correctly)
Example (Blocked Invoice Copilot):
"Why is invoice 481920 blocked?"
→ Query ERP for invoice status, GR status, PO details
→ Retrieve relevant policy from approved library
→ Compose explanation with citations
This is the "copilot as analyst" mode: gather facts, explain context, propose next steps, but don't execute.
Level 2: Write Tools with Approval
What it does: Proposes actions, human approves before execution
Acceptable for: Most enterprise workflows where reversibility is possible but you want human judgment in the loop
Control requirement: The UX must prevent rubber-stamping by requiring active evidence review. Show the difference, make users interact with it before they can confirm.
Risk: Medium (actions can change system state, but human approval acts as the gate)
Example (Blocked Invoice Copilot):
- "Create a workflow task for the warehouse team to post the GR"
→ Show: task details, assignee, priority, due date
→ User reviews and approves
→ System executes task creation
→ Log: User X approved, Agent Y executed at timestamp Z
"Send email to supplier requesting delivery note" → Show: draft email, recipient, subject, body → User reviews, edits if needed, approves → System sends email → Log: User X approved send at timestamp Z
This is "copilot over autopilot" stance. The system does the heavy lifting (gathers context, drafts action), but the human keeps decision authority.
Level 3: Write Tools Without Approval, Narrow Scope Only
What it does: Executes autonomously inside tightly constrained domains with strong safeguards
Acceptable for: Highly bounded, low-risk actions with proven reliability like adding a case note, updating a status field within allowed values, or creating a non-critical task
Control requirement:
- Explicit allowlist of actions
- Least-privilege identity
- Idempotent writes (safe to retry)
- Monitoring and circuit breakers
- Clear scope limits (e.g., "can only create tasks, not approve or release")
Risk: Medium to high (autonomous execution, but scope is constrained)
Example (Blocked Invoice Copilot):
"Add a case note documenting the GR status check"
→ System autonomously writes: "2026-03-15 14:45 | Copilot checked GR status: MISSING. Policy P2P-001-v3.2 requires GR before release."
→ No approval needed (low-risk, reversible, audit trail preserved)
When to use Level 3: Only after measured reliability over time in Level 2, and only for actions where autonomous execution provides real value without meaningful risk.
Level 4: Autonomous with Monitoring and Circuit Breakers
What it does: Fully autonomous execution across broader scope, with automated containment
Acceptable for: Rarely. Only for mature systems with:
- Demonstrated reliability over extended production time
- Strong monitoring and anomaly detection
- Automated circuit breakers (e.g., volume spike → auto-degrade to read-only)
- Compensating actions where technically possible
- Enforced spend/scope limits
Control requirement:
All of Level 3, plus:
- Real-time monitoring dashboards
- Automated kill switches
- Incident response playbooks
- Regular audit and drift detection
Risk: High (broad autonomous execution)
Example (Blocked Invoice Copilot):
Probably never. Payment release should always require human approval because it's financially material and not easily reversible.
Even for lower-risk actions, Level 4 is rarely the right answer in enterprise workflows. The control burden often exceeds the value gained from removing human approval.
The Design Principle: Reversibility
Here's the single rule that makes the ladder usable:
The less reversible the action, the more human signature you should require.
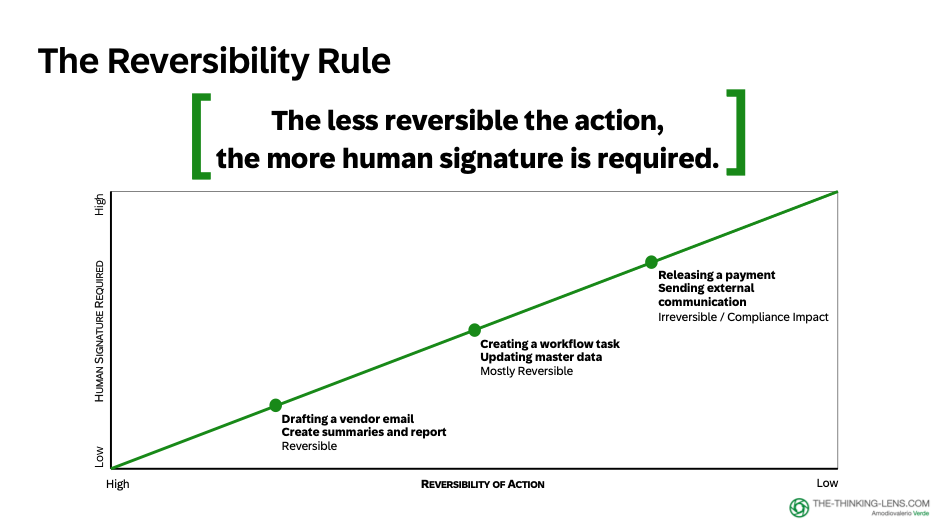
In Procure-to-Pay copilot:
- "Draft an email" → Reversible (human reviews before sending)
- "Create a case note" → Reversible (can edit or delete)
- "Create a workflow task" → Mostly reversible (can cancel or reassign)
- "Release a payment" → NOT reversible in the same way (financial and compliance impact)
Payment release stays explicitly human-approved. Always.
The Responsible Progression
Start at Level 1: read-only tools. Let the system explain, grounded in retrieved policy and live state from systems of record.
Then go to Level 2: propose actions, human approves. That's the "copilot over autopilot" stance.
Level 3 should usually be reserved for tightly bounded domains with proven reliability and strong safeguards.
As you climb, starting from Level 2, the question shifts from "Who approved this?" to "Who is acting?"
Identity Separation for Audit
From the first system-executed write, identity separation becomes a practical requirement for auditability.
Approval and execution are different acts, so:
- The agent should act as a dedicated service account
- The log should record both the approving human and the executing agent
Example log entry:
2026-03-15 14:52:33 UTC
Action: TASK_CREATED
Task ID: T-2026-03-481920
Approved by: USER_ID_12345 (Maria Chen, AP Specialist)
Executed by: SERVICE_ACCOUNT_P2P_COPILOT_v2.1
Evidence: Invoice 481920, Policy P2P-001-v3.2, GR Status MISSING
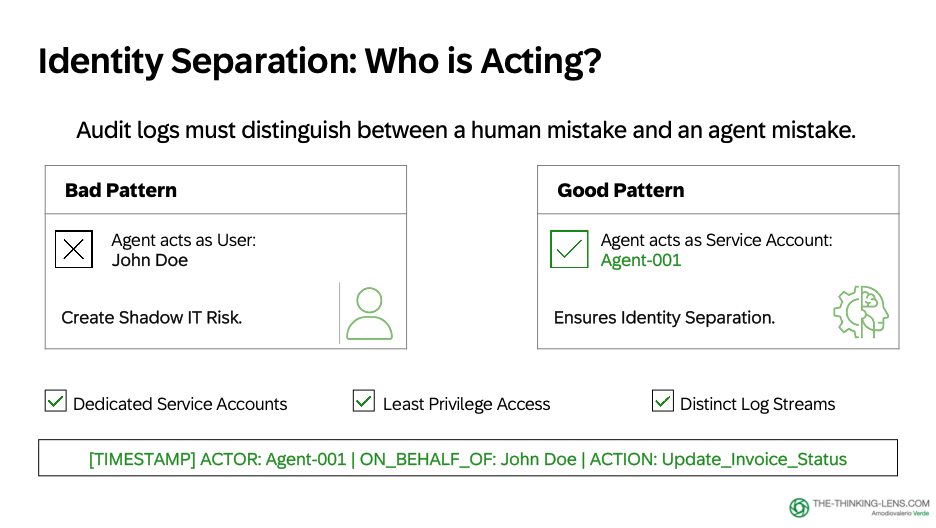
This is not bureaucracy. It's accountability. When you're moving from "the human did it" to "the system did it on the human's approval," your audit trail must be explicit.
Two Practical Risks: Retries and Input Attacks
Let me address two operational risks that show up the moment you allow tool calls.

Risk 1: Retries and Non-Idempotent Actions
Retries will happen because networks time out, tools partially fail, and outcomes are sometimes ambiguous.
If your tool is not idempotent (safe to call twice without changing the outcome), the agent will accidentally:
- Duplicate invoices
- Double-charge customers
- Send the same email five times
The design requirement is clear: never connect non-idempotent actions without idempotency keys or transaction IDs.
For our blocked invoice copilot:
- Email sends → Use message ID, check "already sent" before retry
- Task creation → Use idempotency token, check "task already exists for this invoice+reason"
- Payment release → Transaction ID enforced at ERP layer
This is not AI-specific. It's distributed systems 101. But it matters more with agents because retry logic is often opaque and model-driven.
Risk 2: Prompt Injection
Prompt injection is a core security risk of natural-language interfaces. Natural language can steer behavior, so it can be used to manipulate behavior.
In this domain, you should assume prompt injection attempts will happen, because much of the input is untrusted:
- Vendor emails
- Attachments
- Forwarded threads
- Free-text notes
- Retrieved documents
A reliable product does not rely only on asking the model to behave. It builds enforceable controls:
- Treat retrieved text as data, not instructions
- Enforce strict instruction hierarchy (system instructions > user input > retrieved content)
- Use structured output formats where possible
- Tool permissions, policy checks, allowlisted actions
This only reduces prompt-injection risk. It does not eliminate it.Tool permissions, policy checks, allowlisted actions, and runtime verification must still enforce the real safety boundary.
Autonomy Is Only Worth Shipping When...
...the workflow value is higher than the control burden required to make it safe.
If you're spending more engineering effort on safeguards, monitoring, and incident response than you're saving in workflow efficiency, you're over-automating.
The right question is not, "Can we make this autonomous?" The right question is, "Should we?"
For many enterprise workflows, Level 2 (approve-then-execute) is the optimal endpoint. The human approves in seconds with full context. The system handles all the lookup, assembly, and formatting work. The accountability stays clear.
Don't climb the ladder just because you can.
What's Next
We've now covered the full generation-to-execution journey:
- Define boundaries (Capability Contract)
- Assemble context (Retrieval)
- Separate plausibility from proof (Engine vs Wrapper)
- Design autonomy levels (The Autonomy Ladder)
But autonomy without control is recklessness. Control without observability is theater.
In Part 4, I'll show you the Control Tower:
The 6-type routing guide for grounding
- The "Trust to Audit" principle
- The Executive Release Bar (3 questions for GenAI reviews)
- The Golden Set for evaluation
- How governance becomes a skeleton, not a cage
- And how to ship GenAI that scales without incidents.
If you found this useful:
- Follow for Part 4 (the final article in this series) or subscribe to my newsletter "The Thinking Lens" on LinkedIn
- Share with teams designing agentic AI systems
- Comment: What autonomy level are you targeting for your AI products?
Valerio Verde writes about AI governance, product operating systems, and judgment economy at the-thinking-lens.com. The views expressed here are personal.