
The Semantic Supply Chain: Capability Contract & Inputs


Part 1 of 4: Capability Contract & Inputs
[Views are my own. Not legal or compliance advice.]
When you last prompted a GenAI application, did it feel like persuading a person or programming a machine?
I still catch myself doing it. I start talking to it like a colleague. The more fluent the output, the more I anthropomorphize. The more I treat it like a "who", the more I forget it's a "what".
For product work, that illusion is dangerous. If you treat the model like a person, you will trust its tone. You will mistake confidence for accuracy. You will assume it "understands" your intent.
And that is the trap: fluent output can feel like truth, but confidence is not correctness.

GenAI is not magic. It's a system.
And systems have boundaries, costs, failure modes, and controls. If we don't fundamentally understand how GenAI fails, we are simply shipping avoidable risk.
The Anthropomorphic Trap
In the enterprise, GenAI now powers our daily workflows. But as LLM providers warn, these models can make mistakes. Those mistakes are costly: support tickets, rework, compliance risks, eroded customer trust.
Models are improving, and they will continue improving, but accountability for the product experience remains with us as product, engineering, and design leaders.
The scalable strategy is not hoping the model behaves. It's building system controls.
This isn't about slowing down. It's about shipping GenAI faster with fewer incidents and clearer accountability.
A Risk Heuristic for Product Teams
Your posture should depend on the risk. Here's the heuristic I use:
Low Risk (Internal/Drafts): For low-impact outputs like notes or prototypes, move fast. Just ensure you follow data-classification rules: use approved tools and never paste confidential data into public models.
Medium Risk (Decision Support): For content that influences decisions, use "guarded speed". This requires visible evidence, draft labels, and lightweight reviews before content leaves your workspace. Treat high-stakes advice as high risk.
High Risk (Material Impact): Classify as high risk whenever the output can write to a system of record, create an external commitment, move money, or materially affect compliance. For these cases, we need "gated execution".
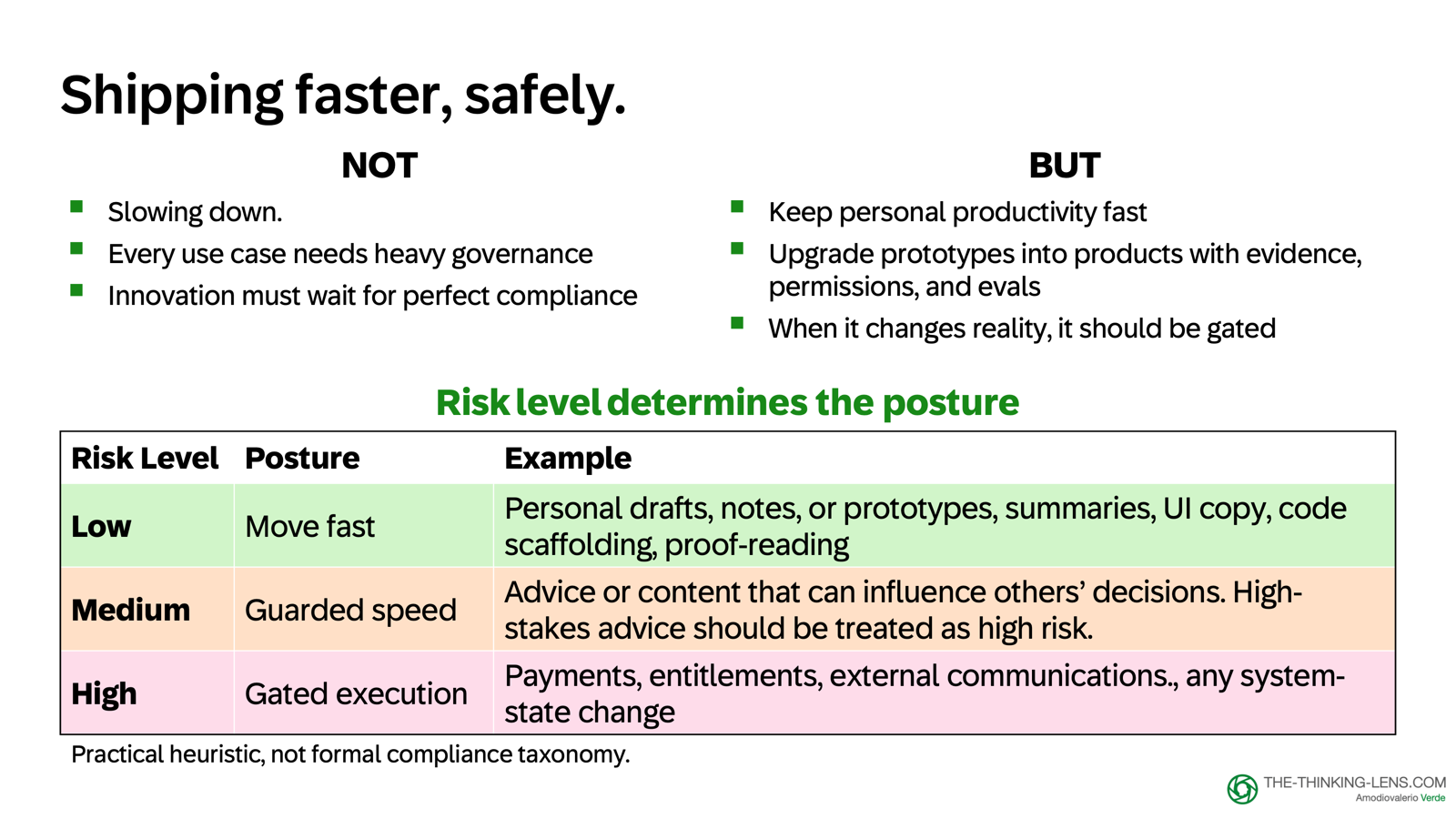
The heuristic in action:
- Low: "Summarize my notes"
- Medium: "Recommend a next step to a customer"
- High: "Send the email, update the record, or release the payment"
This is a practical heuristic for product teams to balance speed and risk, not a compliance classification.
The Semantic Supply Chain: Six Stations from Language to Action
Reliability is a property of the end-to-end system, not the model alone. I map this through what I call the Semantic Supply Chain, the pipeline that turns language into decisions and actions.
We need observability across the whole chain, so behavior is visible, measurable, and governable.
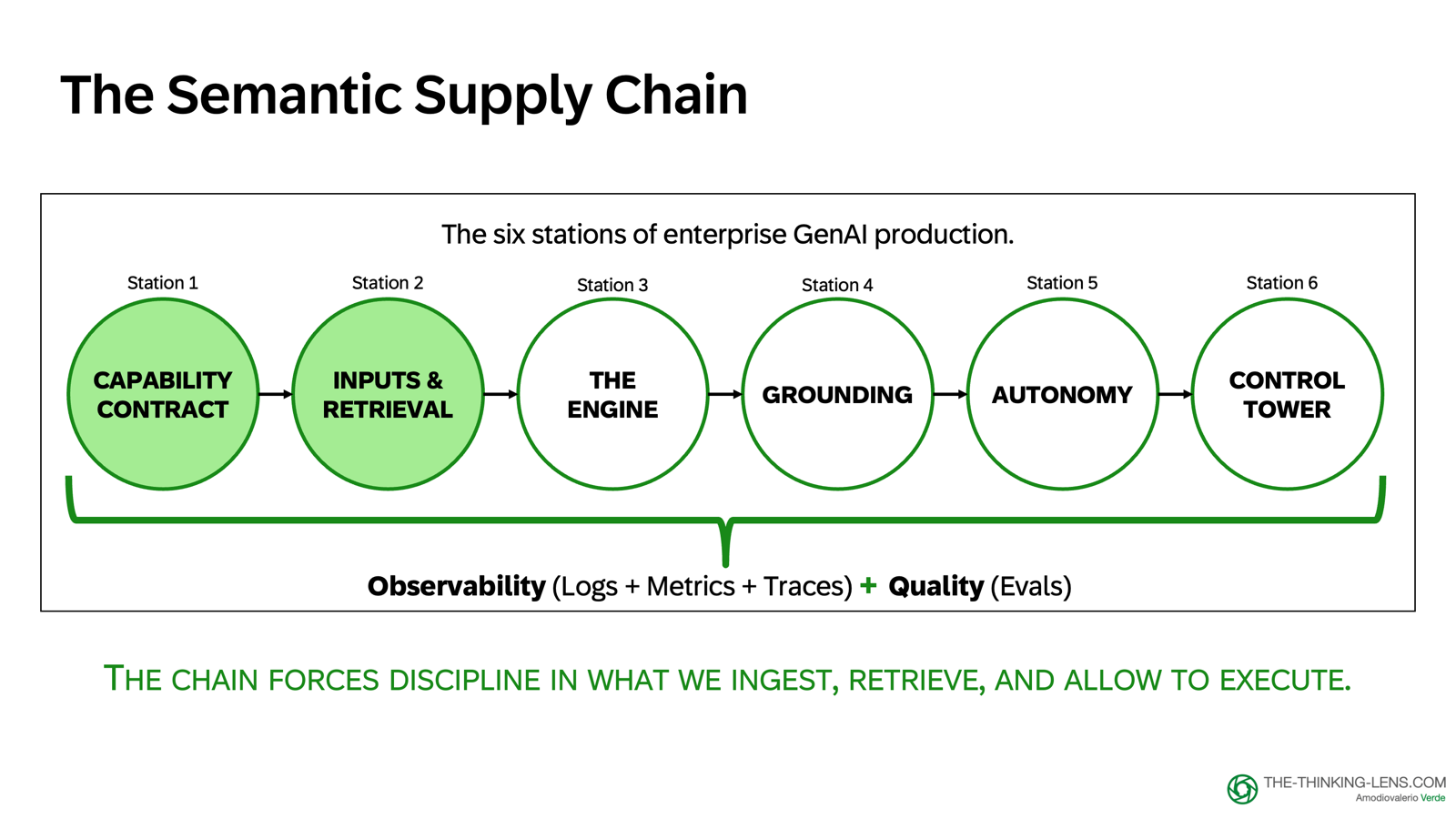
The six stations that matter most when shipping GenAI in the enterprise:
- Capability Contract – Define what the AI may do, must never do, what data it can access, and what evidence it must show
- Inputs & Retrieval – Manage token budget and assemble a small, allowed, relevant candidate evidence set
- The Engine – Understand that the model produces plausible language, not proof
- Grounding – Turn fluent output into traceable, auditable answers backed by evidence and systems of record
- Autonomy – Decide what the system may execute by itself vs. what requires human approval
- Control Tower – Measure quality, monitor behavior, and keep autonomy safe enough to scale
You don't need to remember all six yet. Just remember there are six stations, and in this series, we'll go through them one by one with the same running case. In this part we will focus on Station 1 and Station 2.
The Case: Blocked Invoice Resolution
Before we dive deeper, let's ground this in one concrete case I'll use throughout the series.
Imagine a global shared-services team handling a high volume of blocked invoices because of mismatches in price, tax, or vendor data. Analytics alone doesn't resolve the exception. People still need to read the invoice, find the policy, and take the right workflow step.
This is where GenAI looks promising. You can imagine a copilot that reads the invoice and related emails, retrieves relevant evidence and context, and helps the user resolve the block faster.
Why this case? Because it forces the right product boundaries.
Blocked invoice resolution is not a lightweight chat use case. It's a system problem involving systems of record, policies, approvals, money, audit, inputs, and outputs. Our non-negotiable boundary: reduce resolution time without letting probabilistic text create financial or compliance decisions.
The measurable goal: fewer touches per invoice and faster resolution, without increasing audit findings or policy breaches. If we get this right, we reduce handling cost, avoid late fees, and let teams focus on higher-value exception work.
GenAI may draft and recommend, but only evidence and controlled workflows may execute. The copilot supports human decisions with evidence, controls, and audit. Crucially, this evidence must come from the system of record, not the model's memory, to ensure we aren't just citing a hallucination.
Station 1: The Capability Contract
A demo is a hypothesis; a product is a commitment.
This is about the discipline that helps your prototype survive security, audit, and real-world scale. Governed speed, not slower speed. Prototype in hours, promote to production only when the contracts are explicit and the operating controls are in place.
When I say "contract", I don't mean a legal contract. I mean enforceable product behavior: permissions, approved tools, evidence rules, and safe fallback.
The Capability Contract defines:
- What the AI may do
- What it must never do
- What data it can access
- What evidence it must show when an output can influence a decision or trigger action
If the contract is not met, the system drops to draft mode or escalates.
And just like APIs have versions, AI Capability Contracts should be versioned too, so teams can roll back safely if a model update changes behavior.
The Contract as a Speed Tool
The contract is a speed tool because it standardizes the approval path and the approval criteria in advance. If teams agree on standard data-classification patterns and pre-approved controls, they stop reinventing governance feature by feature.
Security can reuse known boundaries. Teams avoid repeating the same review for every prompt change, for example when risk level or contract didn't change.
The goal is fast and safe, not slow and safe. And the contract is a dial, not a switch: strict where risk is high, lightweight where risk is low.
If you add controls late, you slow down twice: once to retrofit the system, and once to rebuild trust after the first incident.
Example: Procure-to-Pay Capability Contract
For our blocked-invoice copilot, the contract looks like this:
- Allowed: Draft an explanation and cite the system-of-record fields used
- Forbidden: Release payment, change vendor master data, or send an external email without approval
- Required Evidence: Invoice ID, vendor ID, policy snippet version, and SoR field provenance
- Retrieval Scope: Only approved sources, with permissions enforced at retrieval plus output safeguards to reduce accidental exposure
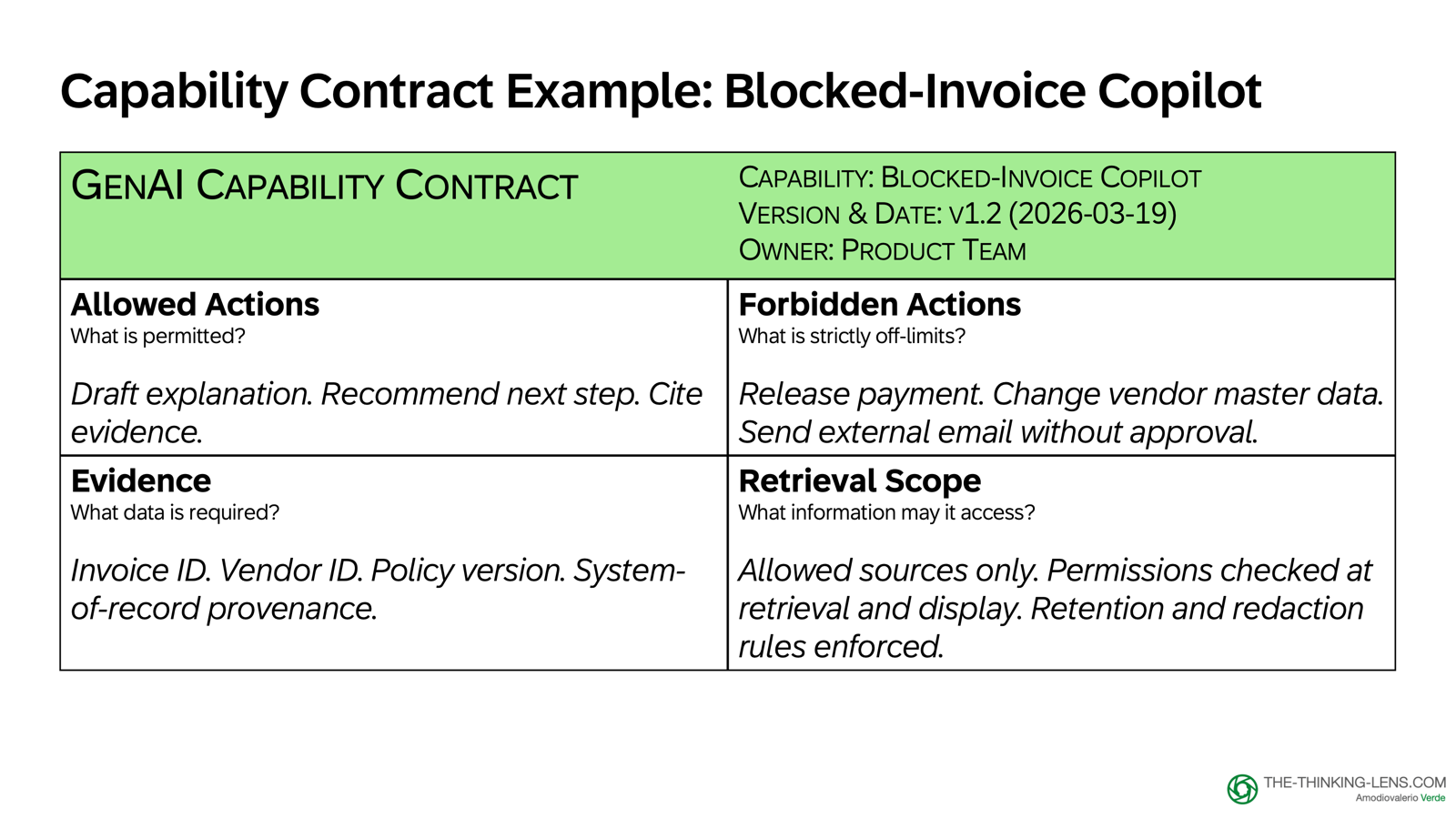
For high-impact or irreversible actions, the safe default is simple: if it's not explicitly allowed, it requires human confirmation or escalation. Drafts can be permissive within permissions and data boundaries. Execution cannot.
The relationship is simple: risk tells us how strict to be, the Capability Contract defines the rules, and the next stations implement those rules in the product.
Station 1 in one line: Define the boundaries and make them enforceable. If the boundaries are vague, the system becomes fragile in production.
Station 2: Inputs & Retrieval
If Station 1 defines the boundaries, Station 2 decides what context enters the system and at what cost.
Tokens set the budget. Retrieval finds relevant candidates through structured filters, exact search, and semantic matching when useful.
Token Economics: The Unit of Language
Tokens are the small units of text the model processes. Every prompt you send and every answer you receive consumes tokens.
Token budget is not a finance detail. It's a product performance spec. It shapes latency, cost, and user experience.
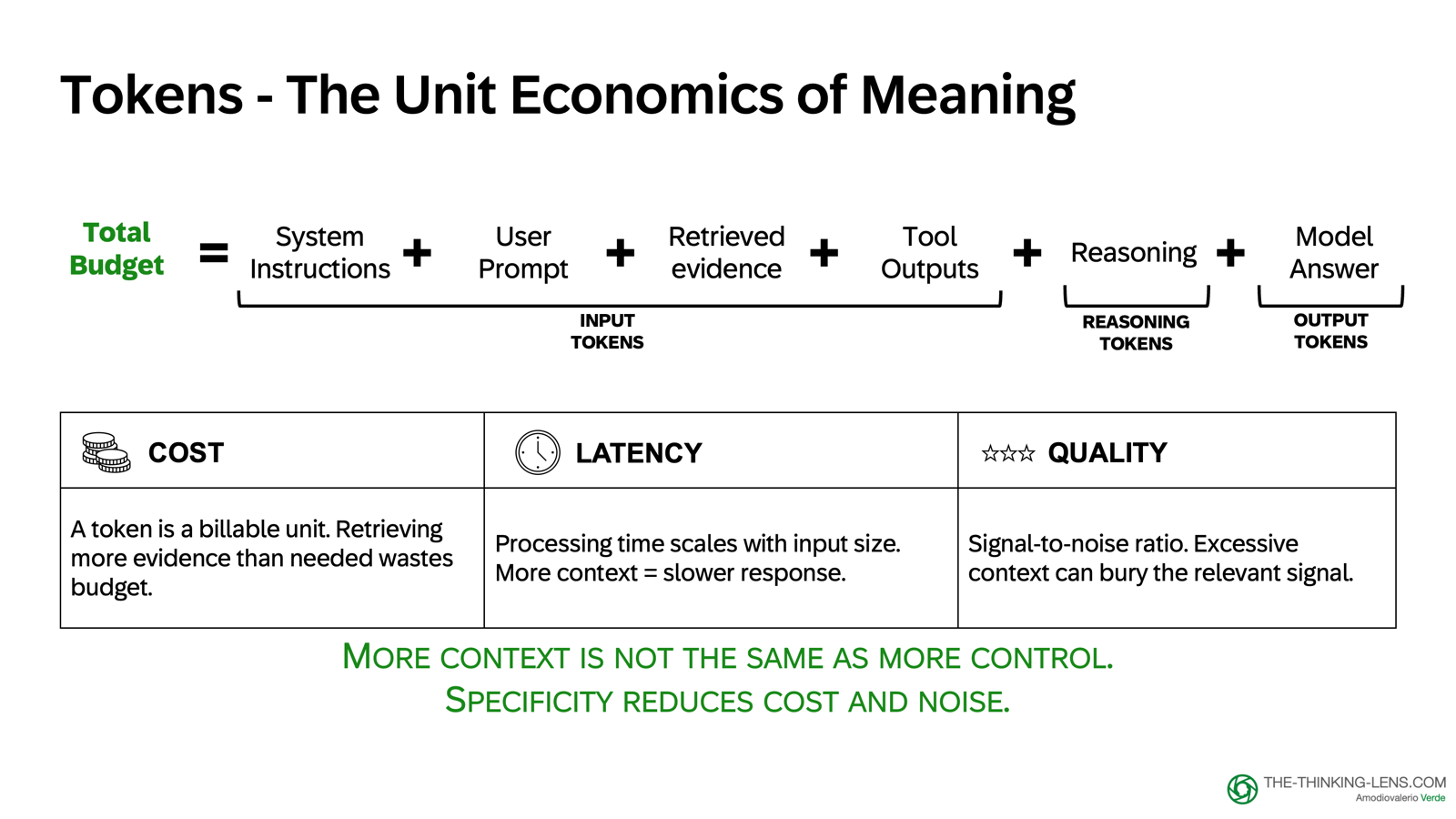
Your budget has two sides:
- Input tokens: system instructions, user prompt, retrieved evidence, tool outputs
- Output tokens: the generated answer
Some reasoning models also consume hidden reasoning tokens. Those are not user-visible evidence, but they still consume context budget and can affect cost and latency.
If you don't manage that budget, you don't control cost, latency, or quality. And for latency, output is usually the slowest part because generation is sequential. But long inputs and tool calls can also dominate end-to-end latency.
The rule is simple: More context is not automatically more control. Usually it just means more cost, more delay, and more noise. Specificity reduces cost and noise.
Embeddings: Ranking, Not Truth
This need for specificity brings us to embeddings, the numerical representations that help semantic matching.
In a product context, treat them as one way to retrieve candidate evidence when wording differs, not as memory, truth, or authorization.
Similarity is only ranking, not truth. High similarity means "looks related". It does not mean "this is correct".
Enterprise Retrieval: Scope and Permissions
In the enterprise, retrieval is not a generic search box. It's a curated evidence pipeline.
We decide what content enters. We decide how it's chunked and indexed. We use exact search, metadata filters, and semantic matching where useful. We retrieve the best allowed candidates for the user's question. Then we pass that candidate evidence forward for grounding.
We measure retrieval quality by whether it brings back useful candidate evidence for the task, not by similarity score alone. Similarity is not confidence. Retrieval needs thresholds, and often reranking, to produce a small, relevant evidence set.
If that pipeline is weak, the model will still answer. It will just answer from the wrong context.
The 4-Point Checklist for Safe Retrieval
- Scope Policy: Define exactly what is indexed and what is excluded, based on data classification, lawful purpose, and risk. Sensitive data like PII should be minimized, protected, and included only when the use case and permissions explicitly require it.
- Permissions: Access controls must be enforced before the prompt is ever assembled. Never retrieve what the user is not allowed to see.
- Metadata Filters: Use structured facts like Region, Role, Date, and Entity to narrow the search space instantly.
- Fallback: If there's no strong match, the system must not guess. Depending on risk, it should either ask a clarifying question, return a bounded "not enough evidence" response, or escalate to a human.
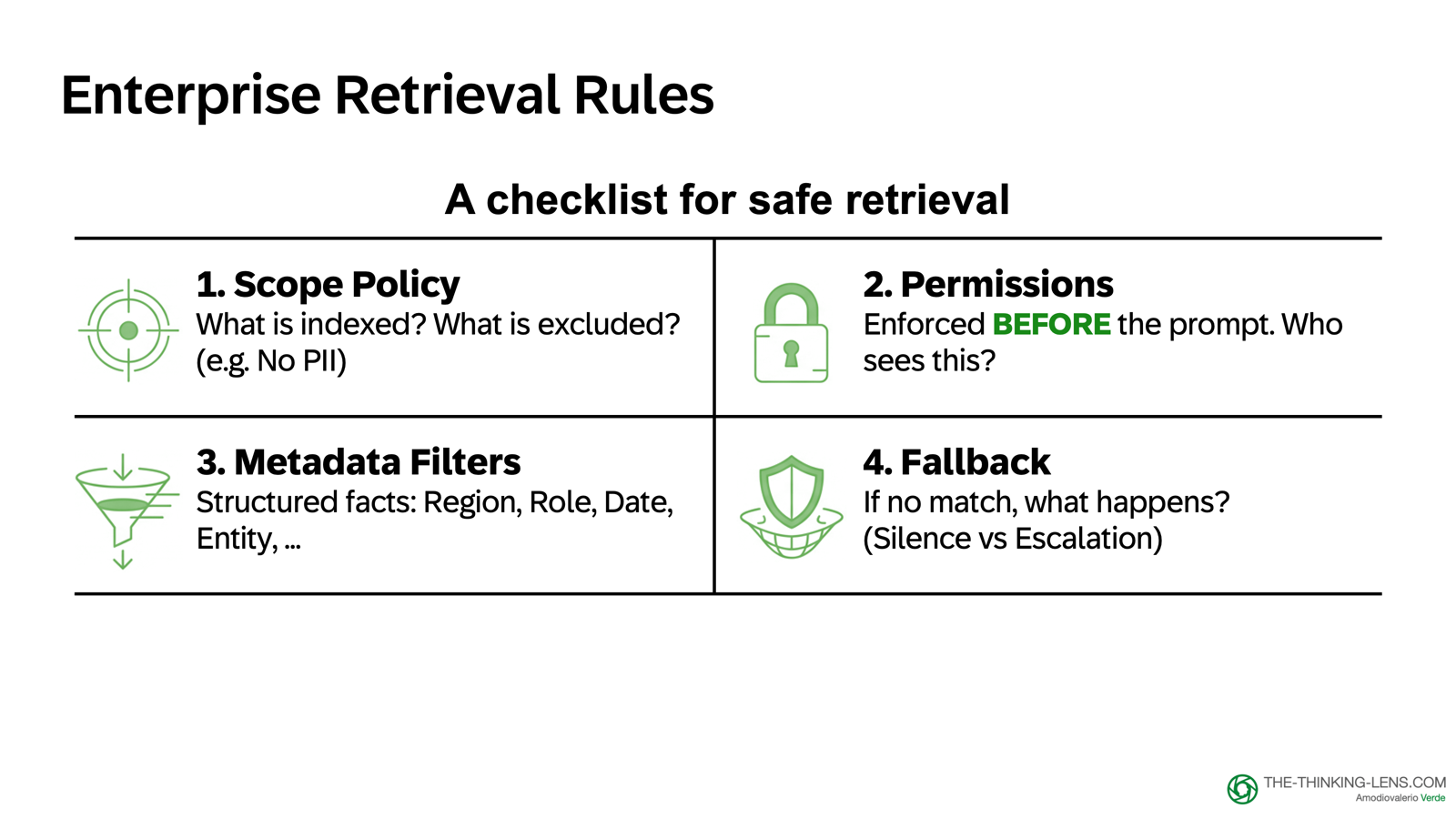
This is why the Contract we defined in Station 1 matters: it sets clear boundaries for what we retrieve, what we exclude, what we only access through tools, and which permissions should be enforced before anything enters the prompt with output safeguards before response delivery.
Hybrid Retrieval Strategy
When you put those rules into practice, you get a hybrid retrieval strategy:
You start with the approved source scope for the specific use case, then apply metadata filters and permissions as hard constraints: role, region, entity, date.
Inside that allowed subset, you run both keyword search and semantic vector search. Keyword search is good for exact terms like vendor IDs, policy names, and invoice fields. Semantic search is good for fuzzy matches and meaning.
You then combine and rerank the results to produce the final evidence set for the prompt.
The design rule is simple: filter first, retrieve second. Don't ask the model to reason about constraints you already know as structured facts.
Example: P2P Copilot Retrieval Strategy
For our Procure-to-Pay copilot, the query is not "search across all enterprise content".
It's: "Search the allowed subset for the exact terms and relevant meaning that apply to this user, this entity, and this context".
User asks: "Why is invoice 481920 blocked?"
Retrieval logic:
- Scope filter: Only P2P policy library + this user's allowed company codes
- Metadata filter: Region=EU, Entity=DE01, Date=policies active as of 2026-03-15
- Exact search: Invoice number "481920", blocking codes, GR/IR terms
- Semantic search: "Why is invoice blocked?" matches policy paragraphs about blocking reasons, tolerance rules, goods receipt requirements
- Combine: Top 5 policy excerpts + invoice metadata
- Pass to model: Small, relevant, allowed evidence set
This is not generic RAG. This is enterprise retrieval with permissions, scope, and fallback built in.
Why This Matters: Cost and Quality
Without tight retrieval:
- You send 10,000 tokens into the prompt (cost: high, latency: high)
- The model must find the relevant paragraph inside that noise (quality: unreliable)
- Risk: The model misses the key rule or invents a plausible-sounding alternative
With tight retrieval:
- You send 500 tokens into the prompt (cost: low, latency: low)
- The relevant policy excerpt is right there (quality: high)
- Risk: Much lower, the evidence is explicit and cited
The difference between these two approaches is not academic. It's the difference between a system that scales and a system that burns budget while producing unreliable answers.
Station 2 in one line: Manage the token budget and assemble a small, allowed, relevant candidate evidence set for the model. That improves what goes into the engine. It doesn't yet determine what is authoritative enough to say.
What's Next
We've laid the foundation: defined boundaries (Capability Contract) and assembled the right context (Inputs & Retrieval). But the real challenge is next:
How do we turn a fluent generator into an enterprise product?
In Part 2, I'll show you why enterprise reliability lives outside the model in what I call the "Wrapper", not the "Engine". We'll explore the critical distinction between plausibility and proof, and the routing rules that determine when to generate, when to look up, and when to refuse.
Valerio Verde is VP Product and Head of Product Excellence. He writes about AI governance, product operating systems, and judgment economy at the-thinking-lens.com.