
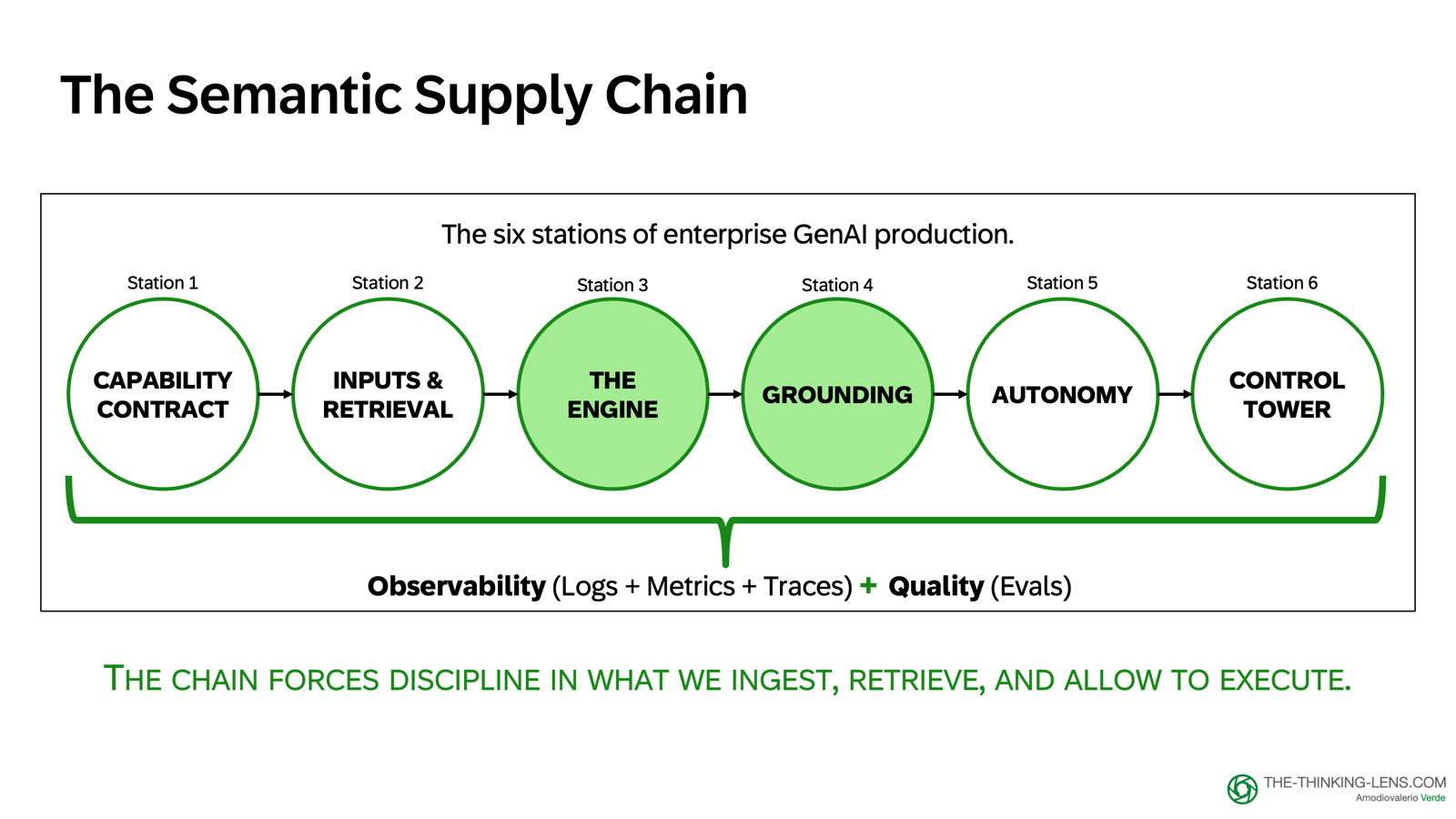
The Semantic Supply Chain: A Product Lens on Enterprise GenAI


Part 2 of 4: Engine and Grounding: From Plausibility to Proof
[Views are my own. Not legal or compliance advice.]
In Part 1, we left off with the foundation: establishing a Capability Contract (Station 1) and building retrieval infrastructure (Station 2) for our Procure-to-Pay copilot case study. We defined what the copilot should do and how it accesses enterprise data.
Now in Part 2, we move to the middle of the pipeline: Station 3 (The Engine) and Station 4 (Grounding), understanding what LLMs actually do and how we bind their output to evidence.
Returning to our running case.
A finance user asks our Procure-to-Pay copilot: "Why is invoice 481920 blocked?"
The model answers with great confidence: "Because the goods receipt is missing."
It sounds plausible. Sometimes it's even right.
But here's the problem: the engine can sound confident without checking enterprise truth.
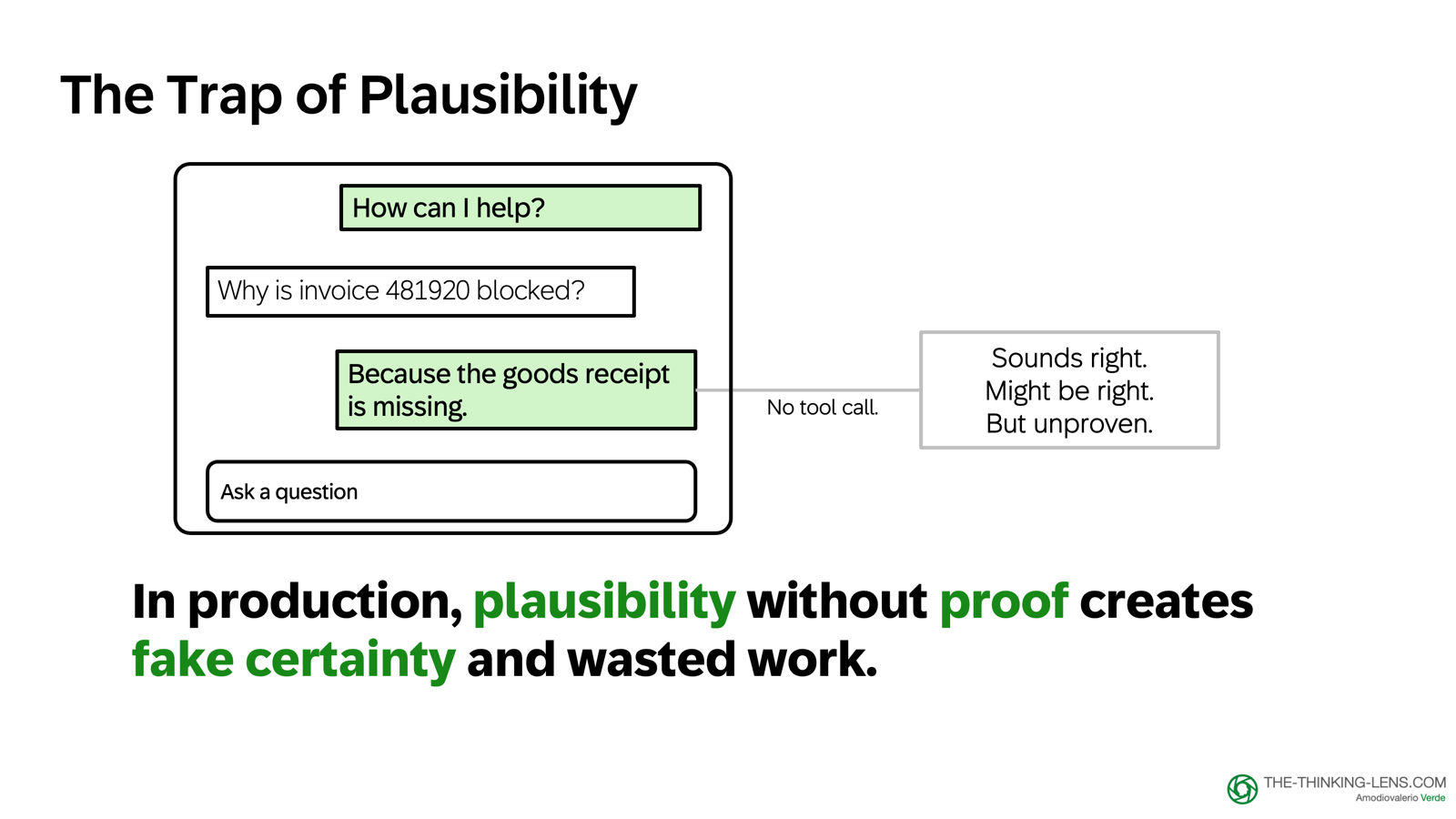
Without retrieval and tool calls, it will often default to a common explanation and wrap it in fluent language. In production, that creates false certainty, wasted effort, and bad decisions.
The cost is not just a wrong answer. The cost is rework, extra chats, extra tickets, and extra escalation loops. It can also mean delayed payments, supplier friction, compliance risk, and loss of user trust.
STATION 3: THE ENGINE - What the Engine Actually Does
An LLM is primarily trained to predict the next token from context, then tuned to follow instructions. It's a powerful text engine, but it's not a database of facts and it's not an authority.
When your product "looks things up" or "searches the web," that's your system using retrieval and tools, not the model doing it on its own.
Let's repeat the key point: Reliability is a property of the full system around the LLM.
The product question is not: "How do we get the model to behave?" but rather: "What controls do we build around the engine so it behaves safely enough for our domain?"
The Hallucination Failure Mode
The common failure mode is simple: when strong evidence is missing, the model fills the gap with the most statistically likely completion. This is called a hallucination or confabulation.
It prioritizes coherence over factual accuracy. It's not lying. There's no intent. It's doing pattern completion under uncertainty.
When evidence is weak, it produces an answer that sounds plausible. That's what the model is designed to do.
Even with strong retrieved evidence, models can still hallucinate by ignoring, misreading, or over-weighting their internal patterns. Retrieval reduces risk, but it doesn't eliminate it. That's why we need checks, evaluations, and safe fallbacks.
There is no single fix here. Reliability comes from system design.
And this is why we keep authoritative business facts outside the model and ground answers via retrieval and tools.
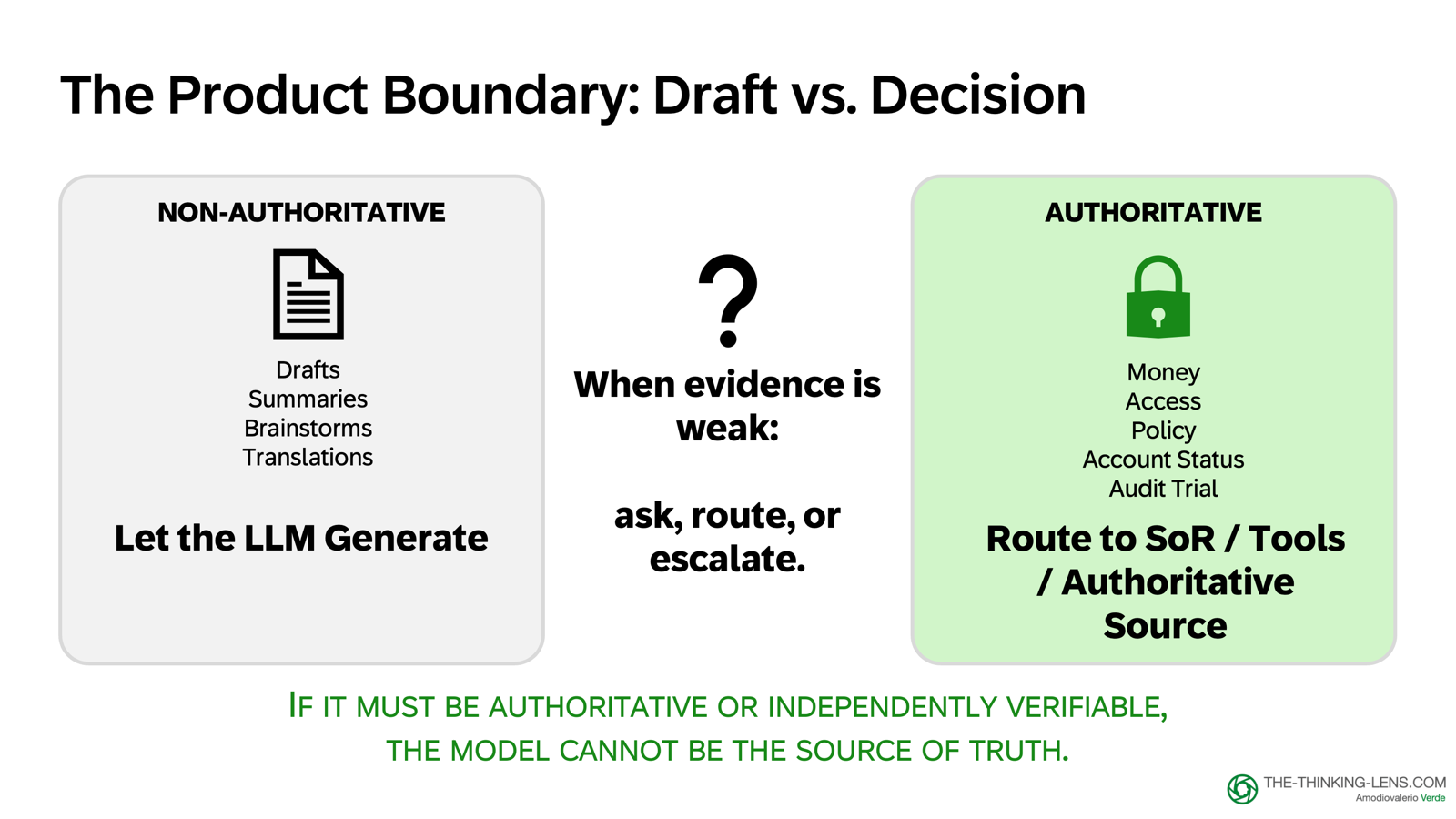
Authoritative vs Non-Authoritative Outputs
Here's the key rule that separates demo from production product:
If the output is non-authoritative (drafts, summaries, brainstorms), you can let the LLM generate.
If the output must be correct or auditable (money, access, policy, account status), the safe default is to route to a tool, system of record, or authoritative source, and let the LLM explain the result.
And when the system is unsure, it should ask a clarifying question, escalate to human confirmation, or refuse to answer in case of disallowed requests.
The key constraint: do not guess.
What Are Non-Authoritative Outputs?
Drafts and transformations: an email draft, a case summary, a checklist, or a clean handover note. These are useful because they save time, and if they're slightly imperfect, a human can correct them.
This is where LLMs shine: they compress work without changing system state.
What Are Authoritative Outputs?
Answers to truth questions:
- "Is the goods receipt posted?"
- "Is the PO still open?"
- "What is the approved tolerance for this company code?"
- "Is the vendor bank account changed?"
- "Can we release the invoice?"
These must come from tools and systems of record. The LLM can help explain the result, but it should not invent it.
In enterprise, confidence without a verifiable source is not a feature. It's a risk.
The Wrapper: Where Enterprise Products Live
LLMs are not the chat applications people use. Those are products built around one or more language models, with UX, tools, and safety layers on top.
This matters because it's easy to assume the intelligence is "in the chat," when much of the reliability actually comes from the application around the model.
Enterprise reliability lives in that application layer, what I call the LLM Wrapper: Retrieval, Tools, Permissions, Logging, Approvals, Refusals
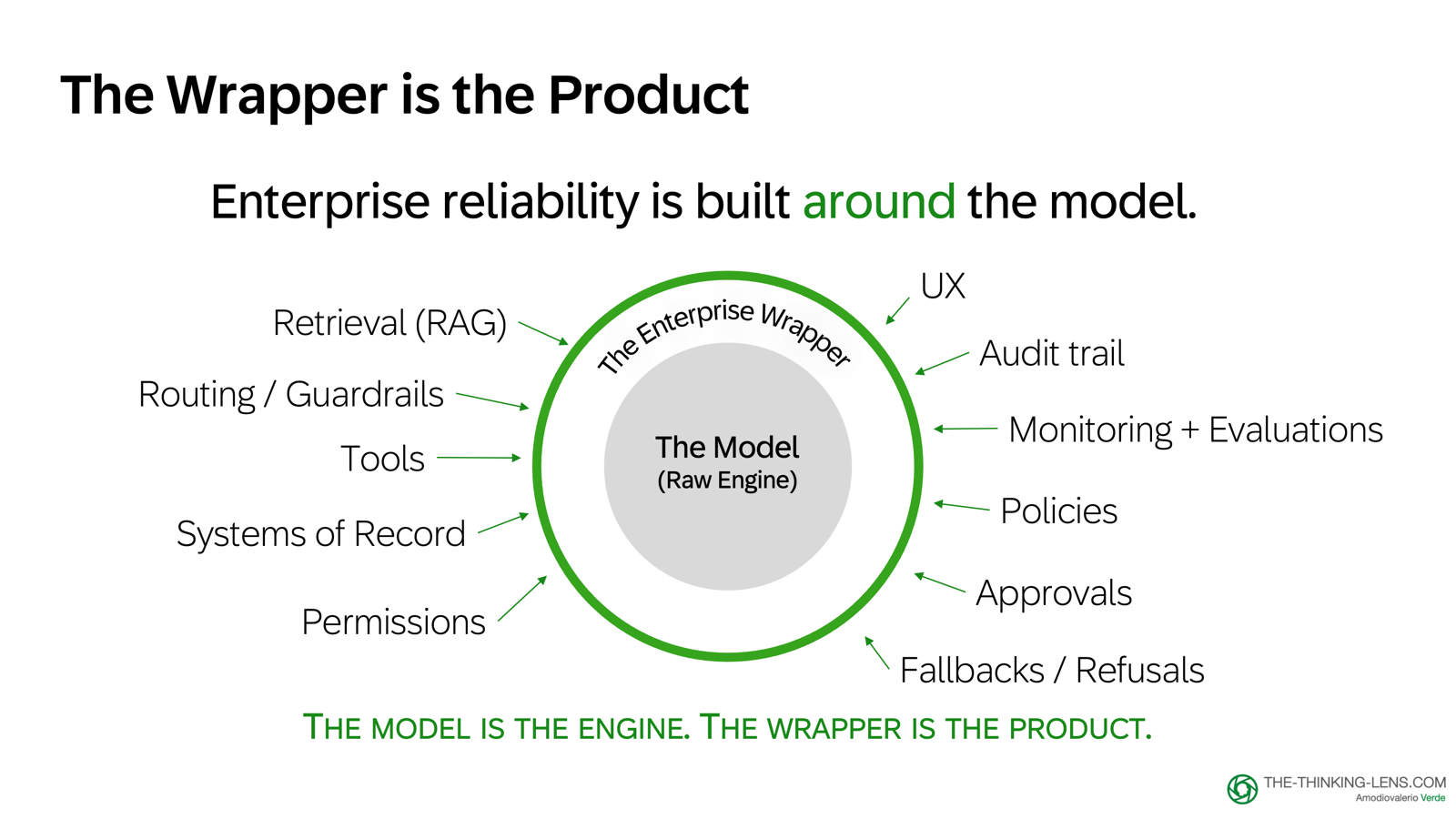
Prompting helps, but enterprise reliability usually depends on broader system design.
The LLM is a powerful engine for language transformation. It can summarize, rewrite, classify, generate drafts, and help humans think. But it is not an authority.
So if you want a copilot that helps resolve blocked invoices, you have to build a system that connects plausible language to system truth.
That means:
- Retrieval for relevant documents
- Tools for deterministic facts
- Clear routing: when to generate, when to look up, and how to fail safely
And that's exactly what Station 4 addresses: Grounding.
STATION 4: GROUNDING - The Grounding Challenge
We've established that the Engine produces plausibility, not proof. Now we need to solve the grounding problem:
How do we turn fluent output into something we can trust and repeat in real workflows?
The answer is grounding, the mechanism that binds fluent output to traceable evidence.
There are three methods, and knowing when to use each is core product intelligence.
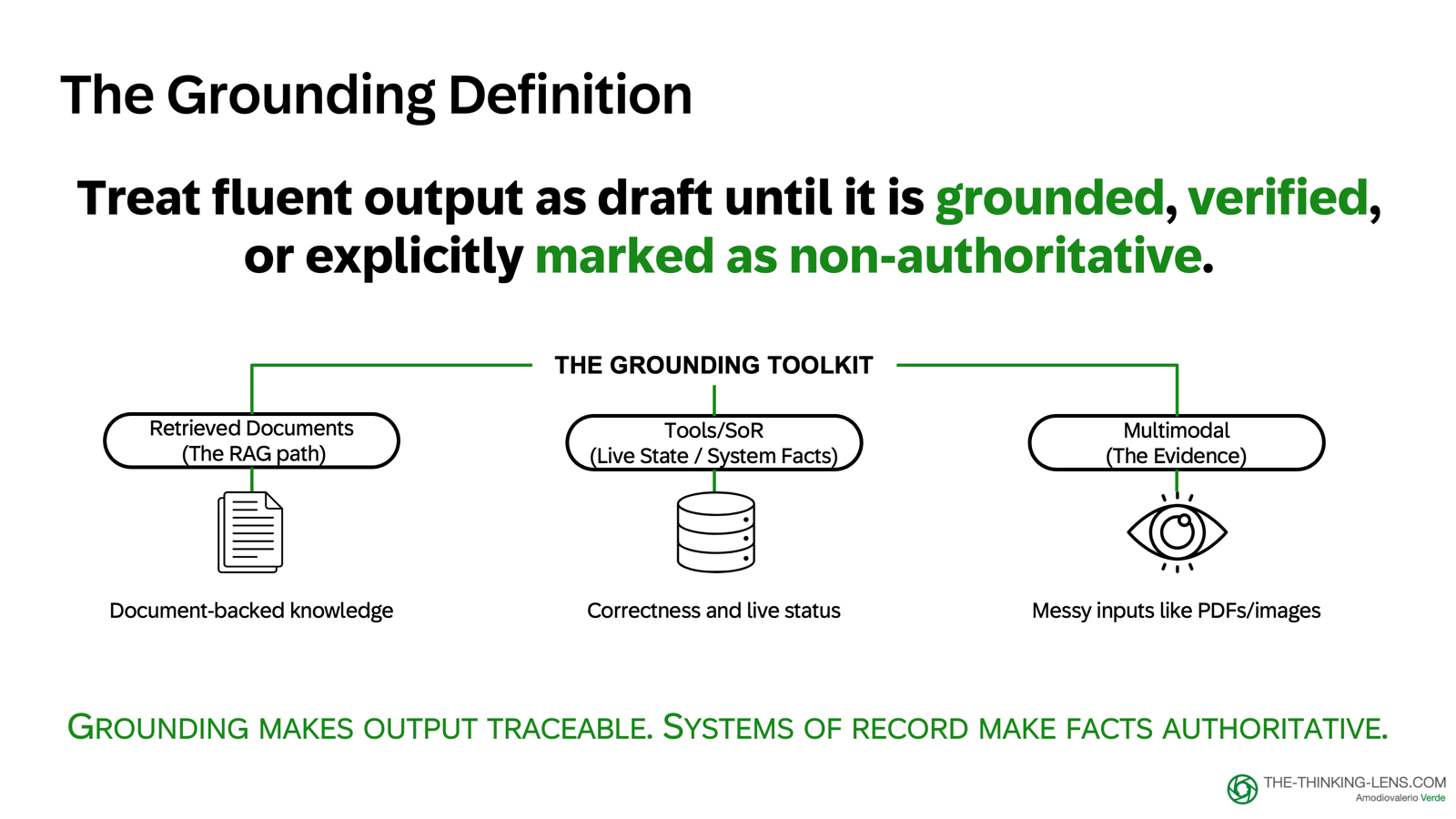
The Grounding Toolkit: Three Methods
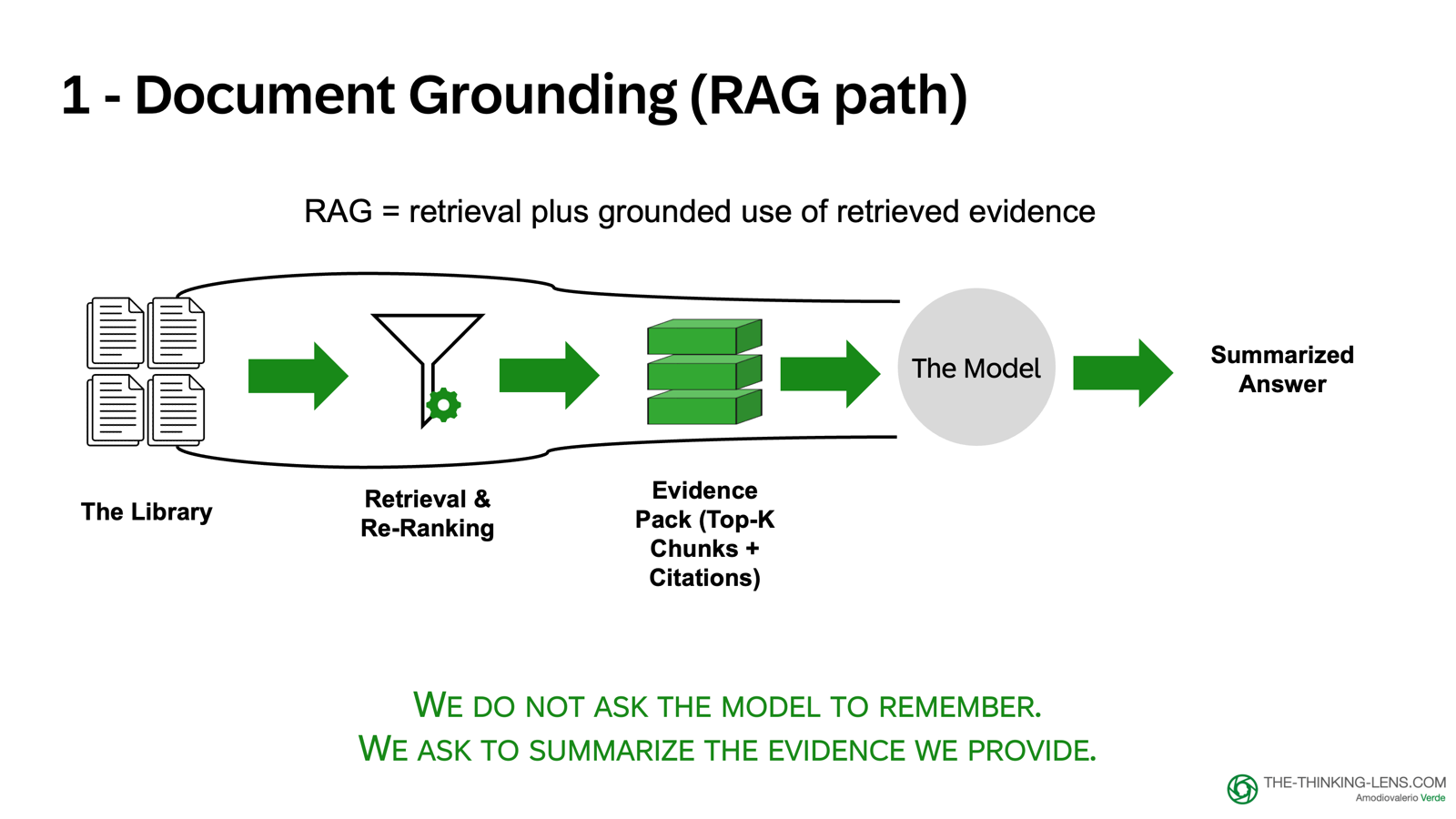
Method 1: Document-Backed Grounding
What it is: Anchoring answers in retrieved policy, playbooks, procedures, and documentation
When to use: For policy questions, procedural guidance, historical context
How it works:
- Retrieve the relevant paragraph or section
- Pass it to the model as context
- Instruct: "If the answer is not in the provided text, say what's missing and suggest the next action. Do not guess."
- Show the source in the UI: document name, version, section, timestamp
Common failure mode: Sending too much text into the prompt and expecting the model to reliably find the right rule. If you bury the rule inside 10,000 words, the model might miss it. And you also increased cost and latency.
The rule: Filter and scope before feeding the model.
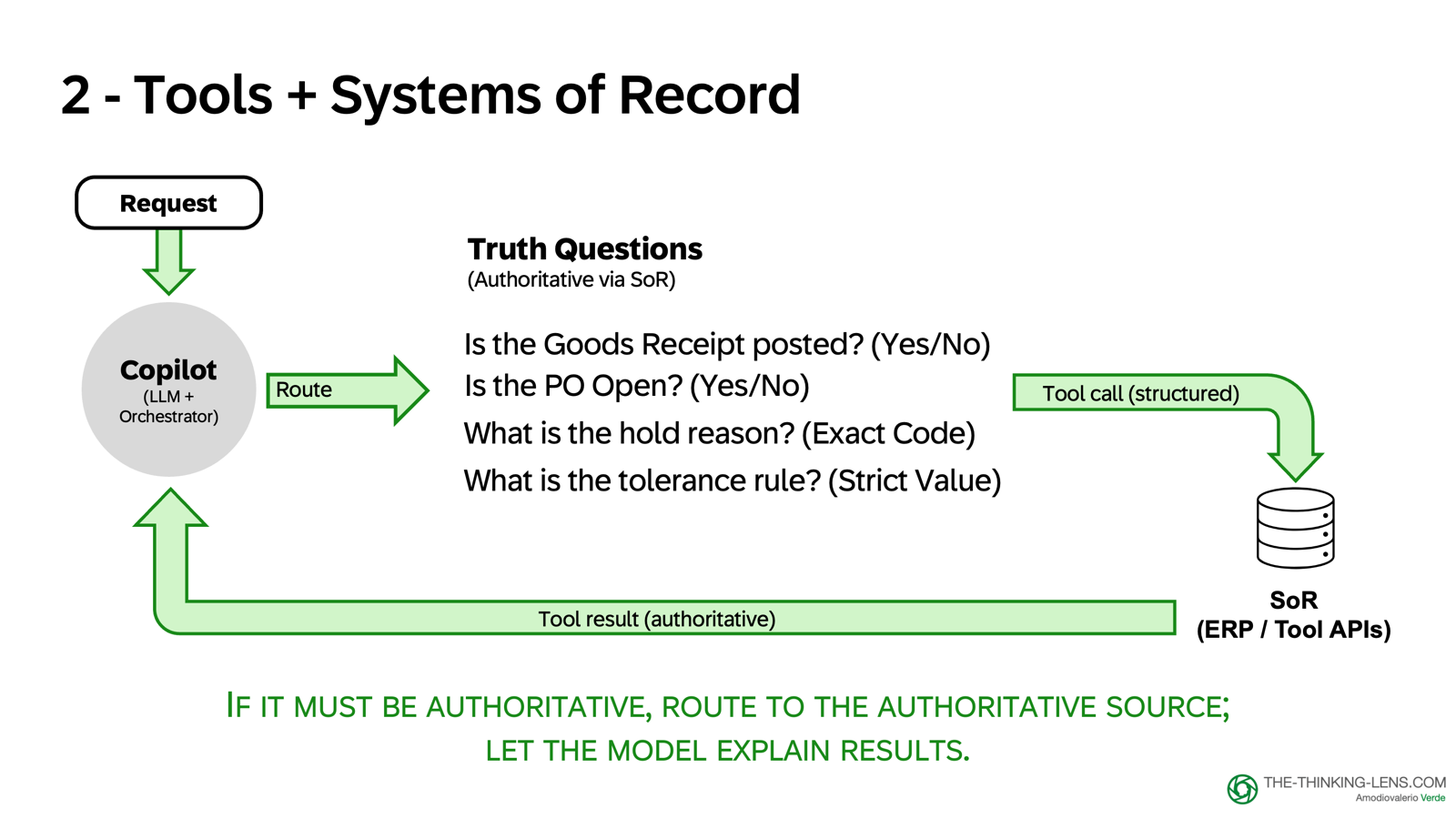
Method 2: Tools and Systems of Record
What it is: Using tool calls to read authoritative facts from live systems
When to use: For truth questions about system state, master data, approval status, configuration
How it works:
- Route authoritative questions to tool calls (not model memory)
- Read from the system of record (ERP, CRM, policy service)
- Log the call: what was queried, when, what was returned
- Let the model explain the result, but the fact comes from the tool
What's deliberately missing: Any action that crosses our risk boundary. We want to reduce resolution time without letting probabilistic text decide payments. The final authority remains with tools, approvals, and humans.
Documents are evidence. Tools are the authoritative source for system state (with timestamps and error handling). The model is the composer.
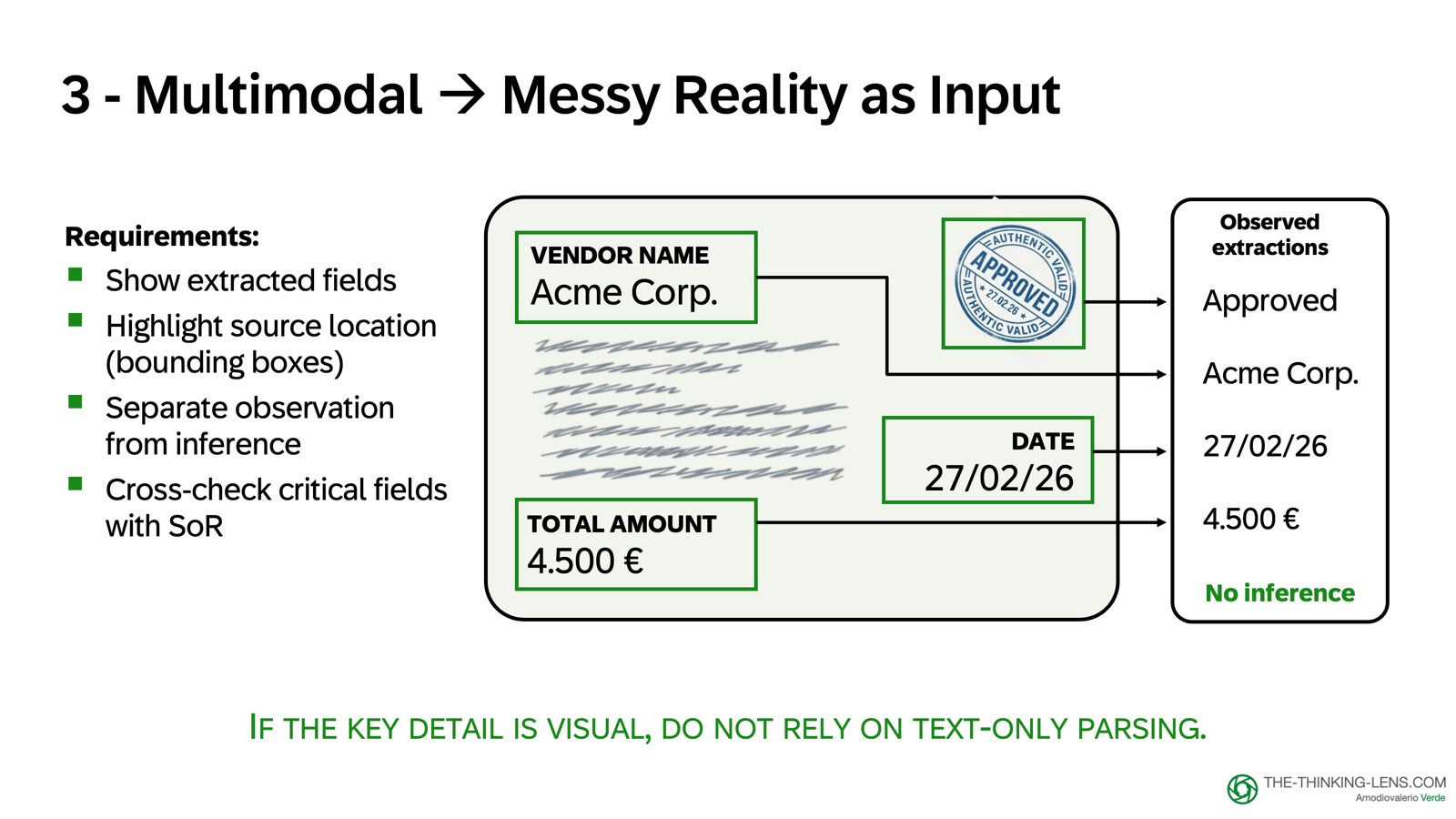
Method 3: Multimodal Extraction
What it is: Extracting information from PDFs, scans, screenshots, images, handwritten notes
When to use: When the truth is visual (tables, header fields, stamps, signatures)
How it works:
- Process the file with a multimodal model
- Extract structured fields (invoice number, date, amount, vendor)
- Show provenance: which page, which section, confidence level
- Separate what is observed from what is inferred
Risk: Multimodal models can sound extremely confident about details they misread. The product requirement is evidence-first: show extracted fields, show where they came from in the document, separate observed from inferred.
Text-only retrieval cannot see images. If the key detail is visual, you need multimodal processing or you accept higher error risk.
Routing Rules: The Product Decision Layer
The routing logic becomes the core product intelligence. Here's the simplified three-type routing guide:
When to Let the LLM Generate
Use Case: Drafts, summaries, reformatting, explanations
Examples:
- "Draft an email to the supplier requesting the missing delivery note"
- "Summarize this case for handover"
- "Rewrite this policy excerpt for a non-technical audience"
Control: Label as draft, show it's AI-generated, require human review before sending
Risk: Low to medium (no system state changes, human reviews before external use)
When to Route to Tools or Documents
Use Case: Truth questions, system state, policy lookups
Examples:
- "Is the goods receipt posted?" → Tool call to ERP system
- "What's the blocking reason code?" → Tool call to system of record
- "What's the approved tolerance?" → Document-backed policy retrieval
- "Calculate the price variance" → Tool call for deterministic computation
Control: Show timestamp, source system, field provenance for tools; show document version, section for policies
Risk: Medium to high (answers must be correct and auditable)
When to Refuse or Escalate
Use Case: Ambiguous requests, weak evidence, disallowed actions
Examples:
- User asks for something outside the Capability Contract
- Retrieval finds no strong policy match
- System state is unclear or conflicting
- Request requires human judgment
Control: Explain what's missing, suggest next best action, route to human
Risk Mitigation: Better to say "I don't have enough evidence" than to guess
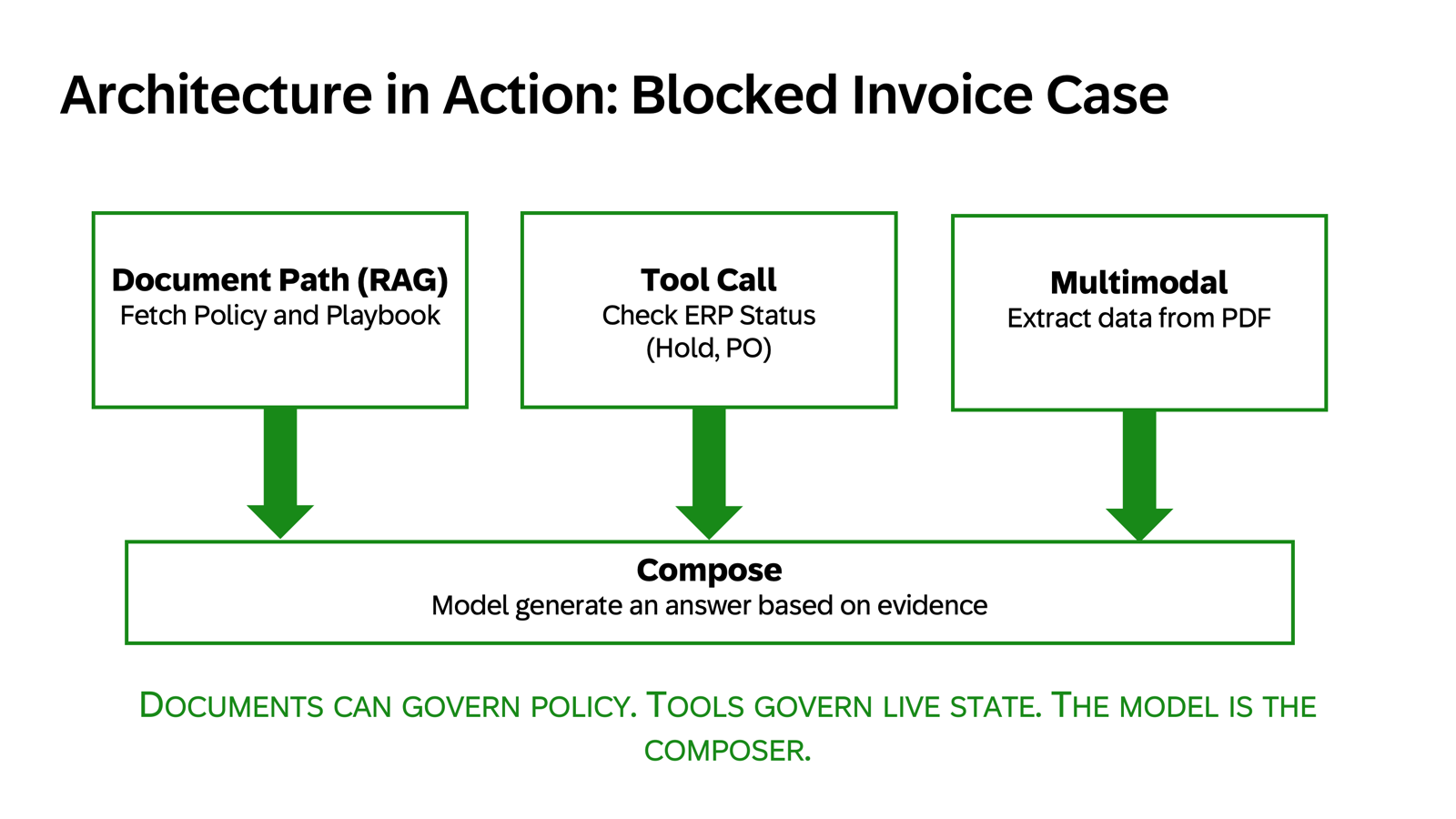
Applying This to the Blocked Invoice Copilot
Let's walk through a realistic interaction that combines Engine understanding with Grounding:
User: "Why is invoice 481920 blocked and what should I do?"
Step 1: Retrieve Candidate Evidence
- Search approved policy library for blocking-reason rules (filtered by company code, region)
- Match invoice type and tolerance policies
Step 2: Call Tools for Live State
- Query ERP: invoice status, hold reason code, PO number, goods receipt status
- Query vendor master data: payment terms, bank account status
- Query approval workflow: who approved what, when
Step 3: Ground the Response
If evidence is strong:
- Generate explanation grounded in retrieved policy + live system state: "Invoice 481920 is blocked because the goods receipt is not yet posted (GR status: MISSING, last checked: 2026-03-15 14:32 UTC). According to policy P2P-001-v3.2 section 4.1, invoices require a matching goods receipt before release."
- Show sources: Link to policy paragraph, show ERP field provenance
- Propose action: "I can create a workflow task for the warehouse team to post the GR. Approve?"
If evidence is weak or conflicting:
- Don't guess: "I see invoice 481920 is on hold (reason code: Z099 - OTHER), but I don't have a clear policy match for this code. I recommend escalating to the P2P supervisor for manual review."
- Escalate with context: Provide what you do know (invoice details, timeline, related POs)
Step 4: Human Decision Point
For low-risk actions (create task, draft email): propose and execute on approval For high-risk actions (release payment, change master data): always require explicit human confirmation with evidence review
The Product Boundary in Practice
This routing logic is not ML ops. It's product design.
The wrapper is where you encode:
- Which questions are "truth questions" vs "transformation questions"
- Which tools the system can call for which entity types
- What evidence threshold is required before answering confidently
- When to show a draft label vs present as authoritative
- Which actions require human approval
The model doesn't decide this. You do.
And that decision framework (the routing rules, the tool permissions, the evidence requirements) is the difference between a promising demo and a production-ready product.
Three Common Mistakes
Mistake 1: Assuming prompting alone will enforce boundaries "I told it not to hallucinate" is not a control. Prompting is an input signal, not a guarantee. Enterprise boundaries must be enforced in code: tool permissions, approval gates, retrieval scopes.
Mistake 2: Treating all outputs the same A draft email and a payment release are not the same risk level. Your UX, labels, and controls should reflect that. Drafts can be generous. Execution must be strict.
Mistake 3: Skipping the "I don't know" path The most important product decision is teaching the system when not to answer. Confident wrong answers are more damaging than clear "I don't have enough evidence" responses.
Why This Matters for Product Leaders
You're responsible for the whole system, not just the model. When an incident happens, "the LLM hallucinated" is not a sufficient postmortem. The questions are:
- Why did we route that question to generation instead of a tool call?
- Why didn't our retrieval find the right evidence?
- Why didn't our confidence threshold trigger a fallback?
- Why didn't our approval gate catch this?
These are product questions, not model questions.
The LLM is the engine. Your wrapper is the product. And enterprise reliability lives in the wrapper.
Station 3 & 4 in one line:
Station 3 (Engine): Understand that LLMs produce plausibility, not proof. Don't trust fluency.
Station 4 (Grounding): Bind output to evidence using documents, tools, or multimodal extraction. Make answers traceable and auditable.
What's Next
We've now covered the input-to-output pipeline:
- Define boundaries (Capability Contract)
- Assemble context (Retrieval)
- Understand the engine (Plausibility, not proof)
- Ground the output (Evidence, tools, multimodal)
But we haven't yet solved execution: When should the system act by itself vs. require human approval?
In Part 3, I'll walk you through the Autonomy Ladder, designing copilot vs autopilot based on reversibility and risk.
Then in Part 4, we'll close with the Control Tower: how to measure quality, monitor behavior, and make autonomy safe enough to scale.
Valerio Verde writes about AI governance, product operating systems, and judgment economy at the-thinking-lens.com. The views expressed here are personal.
If you found this useful:
- Follow for Parts 3-4 of this series
- Subscribe to my newsletter "The Thinking Lens" on LinkedIn
- Share with product teams building enterprise GenAI
- Comment: how do you ground AI outputs in your products?