
The Parrot and the Library: Why AI Won't Kill Search (It Will Crown It)
AI will not kill search; it crowns whoever controls a fresh index. Synthesis engines give fast answers but depend on live, trusted crawling for freshness, coverage, and provenance. The future is hybrid: shelves and summaries, with winners owning both discovery and explanation. Clicks fund freshness.


TL;DR
- Search isn’t dying, but search engines as we know them are. Generative AI is already siphoning traffic from publishers and pushing users toward one-answer experiences.
- TikTok, YouTube, and AI chatbots are training an entire generation to bypass Google altogether.
- The paradox: AI can’t survive without live indexes, yet its growth threatens the ad economics that keep those indexes fresh.
- Cut the ad stream and the library rots; let AI starve and convenience disappears.
- The future belongs to players who own both shelves and summaries, but challengers will emerge where incumbents are weakest: in verticals like ecommerce, travel, and local services.
- The real question isn’t “Will AI kill search?” It’s “Who controls the index when the clicks dry up?”
As a systems thinker in product, I'm fascinated by how massive technological shifts reconfigure entire ecosystems. The current debate around 'AI vs. Search' is a perfect example. I wanted to step back from the hype and analyze the underlying mechanics. In this article, I share my personal perspective on why AI and search aren’t competitors, they’re partners shaping the next phase of digital discovery.
Let’s break this down.
The Death of Search? Not Quite.
Every few months, the headlines repeat: “AI will kill Google” “Search is dead” or “Soon, we won’t need browsers, just ask an AI”. The truth is more complex. Search isn’t dying. It’s being dismantled and rebuilt in real time.
Generative AI has already reshaped how millions discover information, collapsing multi-step browsing into one-answer experiences. At the same time, platforms like TikTok and YouTube are training younger generations to bypass Google.
But here’s the paradox: AI can’t replace search. It feeds on it. Strip away the indexes that keep the web fresh, and synthesis engines turn into parrots whispering from stale data.
So the real question isn’t whether AI will kill search. It’s who will control the index once the clicks (and the ad dollars) start to dry up.
Search Engines: The Libraries of the Digital Age
A search engine is not just a box you type into. At its core, it’s the largest, fastest, most obsessive librarian in history.
What it does best:
- Crawls and ranks as much of the web as possible.
- Returns original sources with minimal interpretation.
- Preserves user agency: you choose which source to trust.
- Enables discovery, even deep into the dusty aisles (page 5, anyone?).
That last point matters. Sometimes the gold is buried. Anyone who’s scrolled past SEO-bait on page 1 knows the thrill of striking a real gem a few pages later.
It’s like digging through a vinyl bin at a flea market: most of it is junk, but when you find that rare pressing… worth the hunt.
Search engines are indexing systems. They don’t summarize; they surface.
They trust you to do the thinking.
AI Systems: The TL;DR of the Internet
Now, AI models.
They don’t crawl the live web. They rely on frozen training snapshots, updated on their schedule. Some can browse, but none maintain a full index. What they do best:
- Summarize and rephrase, not deliver raw sources.
- Filter results: convenience with bias.
- Optimize for efficiency, not coverage.
- Answer in natural language, like a confident friend.
Sounds convenient, right? It is. But convenience comes at a cost. Ask an AI for a quick answer, and you’ll often get one. Ask it to let you stumble across the unexpected, not so much.
And then there’s the accuracy problem.
AI is like that friend who tells a great story but sometimes adds details that never happened.
In the industry, we call this “hallucination.” Which is a polite way of saying: it makes stuff up.
That’s why I call them synthesis engines. They don’t show you the shelves. They give you the summary. But sometimes, they slip in a few pages that were never in the book.
Most modern “chat search” tools already blend the two worlds through retrieval-augmented generation (RAG): they pull a handful of fresh documents in real time, then let the model write the answer. RAG proves that synthesis does not replace indexing, it leans on it while hiding the seams from the user.
The Gaps That Keep Search Alive
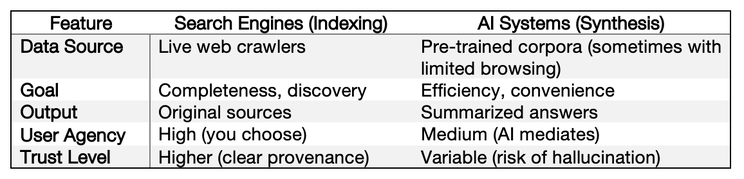
This is where things get interesting. The biggest reasons AI won’t replace search, at least not yet, are the gaps only indexing systems can fill:
- Freshness: Indexes update in near real time, paid for by the ad machine that funds crawling. Synthesis engines run on frozen snapshots, which means they lag and risk parroting yesterday’s web.
- Coverage: Search engines are built for immense scale, indexing billions of new pages daily to provide comprehensive and exhaustive results. This scale, which requires massive infrastructure, is what enables true discovery, allowing users to find the "real gem" buried pages deep, not just the polished content on page one. AI systems, which are not built for this level of global crawling, are instead optimized for efficiency, not exhaustive coverage.
- Transparency: A core function of an indexing system is to return links to original sources with minimal interpretation, showing clear provenance for its information. This allows you to see the source for yourself when trust is critical. Synthesis engines, conversely, often deliver a rephrased summary that can obscure the original source, introducing a layer of mediation and potentially hiding what information was filtered out in the name of convenience.
- User Agency: Indexing systems are designed to preserve user agency by surfacing a range of sources and trusting you, the user, to do the thinking and decide which source to trust. This gives you completeness and control over the discovery process. Synthesis engines optimize for convenience by providing a single, mediated summary, a shortcut that streamlines the journey but reduces your role in exploration and direct evaluation of competing sources.
- Legal & Ethical Provenance: Indexes respect copyright by design: they point, they don’t copy. Synthesis engines live in a contested legal zone, trained on data often without consent. That makes indexes a safer harbor for verifiable provenance.
And let’s not forget trust. When you’re deciding which medication to take or how to invest your savings, “ChatGPT said so” doesn’t cut it. You want to see the source.
While challengers will try to build trust through brand reputation and specialization, they cannot easily replicate the trust signal of verifiable grounding. An incumbent's AI can build superior trust by not just providing a synthesized answer, but by demonstrating how it arrived at that answer, citing a comprehensive, live index of sources in real-time. This ability to provide real-time transparency is a form of trust that a niche AI with a more limited dataset will struggle to match.
Where the Real Disruption Hits
Here’s the twist: The real threat of AI isn’t to general search. It’s to verticals where synthesis beats browsing.
Think about it.
- E‑commerce: Why scroll through ten tabs comparing the same sneakers when an AI agent can find the best price, in your size, including shipping, in under 30 seconds? That’s not just convenience. That’s an arms race sellers can’t ignore.
- Travel: One prompt can now find the cheapest flight and a Midtown hotel in seconds. But under the hood, it still queries legacy GDS platforms like Amadeus, Sabre or TravelPort for live fares. The dependency hasn’t vanished.
- Local services: Need a plumber tomorrow? An AI assistant skips Google Maps and Yelp, booking you directly with a 4.7-star provider nearby. Goodbye, scrolling.
- Factual lookups: For quick “what year did X happen?” queries, AI already reduces traffic to sites like Wikipedia and to blogs. And let’s be honest: most of those sites aren’t built for revenue anymore.
Notice the pattern? AI wins where the task is narrow and structured. Where you don’t want to explore, you just want it done.
General search? Still safe. But vertical search players? They should be cautious. If you run a vertical search business, assume AI is already rewriting your funnel.
The Economics No One Wants to Talk About
Let’s zoom out.
Search engines aren’t just magic. They’re funded by an economic machine: ads. Massive infrastructure for crawling, ranking, and indexing funded by ad dollars. You search “running shoes,” brands pay to appear. That money pays for the infrastructure that keeps the index fresh.
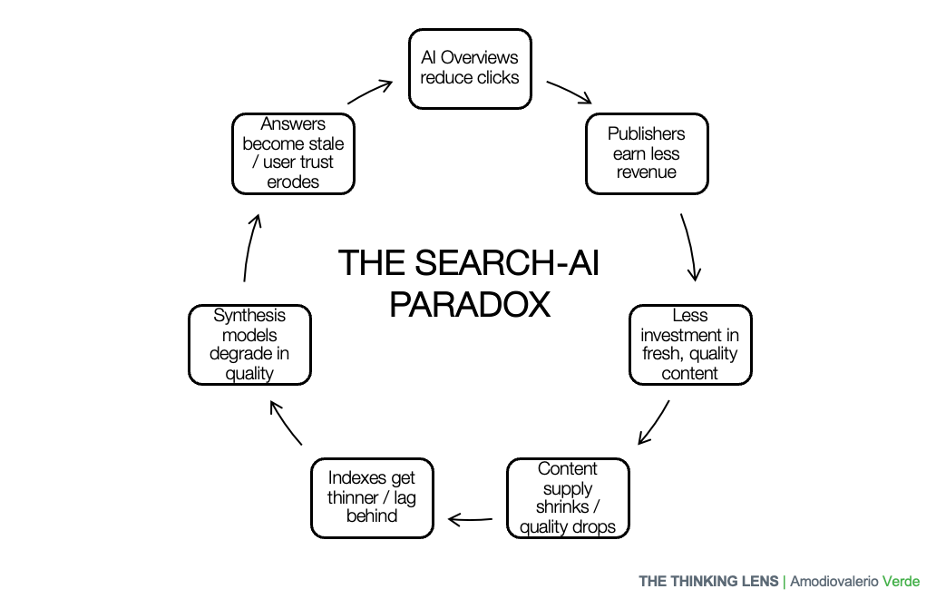
Here’s the problem: If AI systems deliver answers without clicks, that revenue vanishes. No revenue, no incentive to crawl at scale. And without crawling, freshness and coverage suffer.
It’s a vicious cycle:
- Less ad revenue → less crawling
- Less crawling → weaker index
- Weaker index → worse search results
- Worse results → more users drift to AI
Google is already placing ads inside AI Overviews. This is not a test on the horizon; it is live and expanding to more surfaces and geographies.
The revenue model isn’t disappearing, it’s shifting from blue links to synthesized answers.
Incumbents’ ad cash flows act as a subsidy engine, letting them fund years of experiments challengers can’t afford. They can afford to lose money perfecting the next model, a luxury challengers running on venture capital simply do not have.
This is amplified by unresolved disputes over data provenance and copyright. Many AI systems trained on content without permission face lawsuits from publishers and artists. This uncertainty reinforces the unique value of indexing systems, which don't claim ownership of content but simply point to the original, credited source, preserving the creator's rights.
It’s like cutting the budget of your city library because “people are reading summaries online.” Great, until you realize those summaries depend on books that someone still has to buy and catalog.
This dynamic extends beyond large publishers to the entire creator economy, where individual writers, artists, and experts see their work being summarized without credit or compensation, threatening the very ecosystem that produces novel human insights.
If indexing systems collapse, synthesis engines don’t replace them. They starve.
The Behavior Shift Already Underway
Now, let’s talk people.
Younger generations already treat traditional search like an outdated ritual. Many don’t “Google it.” They TikTok it. They ask YouTube. They fire up an AI chatbot.
For them, discovery isn’t a blue list of 10 links. It’s a video feed. Or a conversational interface.
That doesn’t kill search engines, but it reshapes demand. If habits shift enough, “classic search” risks becoming the tool of researchers, professionals, and the old guard.
Think about music: Remember when owning CDs was the default? Then iTunes made downloads the norm. Then Spotify made owning music feel unnecessary. Search is in its Spotify moment. Still alive. Still needed. But increasingly hidden behind layers of convenience.
Question for you: When was the last time you willingly went to page 5 of search results? Or did you just tweak your query and trust page 1?
When to Trust the Synthesizer, When to Fall Back on Search
Yes, we’ll still need classical search, but mostly as power mode and fallback. For a growing share of tasks, the default entry point is a synthesizer with usable answers and sources.
Use a synthesizer when: the goal is clear, stakes are low, and speed matters. Think “explain, compare, outline, quick plan,” or one-shot tasks where one good answer is enough. Use classical search when: intent is navigational or investigative, you need breadth and control, freshness is critical, or the decision is high-stakes.

What’s driving the shift: technology unlocked it, behavior locks it in. Quality LLMs with grounding made single-shot answers viable; once trust and citations are good enough, users prefer convenience.
Net: synthesis-first UX on top of a live index, with a visible path back to raw results when provenance and control matter.

Product implications:
- Build synthesis-first, but keep an always-visible path to the raw results set.
- Show provenance by default. Let users “expand to evidence” and “open the index.”
- Detect intent. Route navigational and investigative intents to search UI automatically.
- Invest in freshness. If you do not own an index, secure high-quality licensed feeds or APIs.
- Instrument trust. Track when users pivot from answer to results and why.
- For enterprise, default to grounded answers with policy, lineage, and audit logs.
The Hybrid Future (Already Here)
The truth? The future isn’t “search” or “AI.” It’s both.
Look around:
- Google’s AI Overviews (formerly SGE) blends indexed results with AI summaries.
- Microsoft Copilot layers synthesis directly on top of live search.
- Perplexity does it more elegantly, citing sources with every synthesized answer.
This is not the death of search. It’s search with a sidekick.
It’s like a buffet: you still want the full spread (the index), but sometimes you grab the chef’s tasting plate (the AI summary) to save time.
Any credible search experience will need both modes:
- Unmediated discovery: links, context, and breadth when you want completeness and control.
- Contextual synthesis: shortcuts, summaries, and recommendations when efficiency matters more than exploration.
Not competing. Complementary. Users will expect to move fluidly between them.
When the Index Owns the Synthesizer
There’s another angle we need to consider: control of the index itself.
The dominant players own both: the world’s largest indexes and state-of-the-art synthesis engines like Google Gemini and Microsoft Copilot.
When a company owns both the index (the shelves) and the synthesizer (the summaries), it doesn’t risk being displaced. It risks becoming a gatekeeper.
This shifts the narrative entirely. AI won’t kill the major incumbents; if anything, it makes them stronger:
- Unmatched foundation: Their mature indexes are an unrivaled data asset. This is not just about the scale of the crawl, but about the two decades of user intent and quality signals layered on top. This understanding of relevance and trustworthiness is the true moat, something a new, commoditized index cannot easily replicate.
- Integrated synthesis: Placing their proprietary models like Gemini or Copilot on top of that index delivers the best of both worlds, live discovery plus instant summaries.
- Economic resilience: The ad-based economic model evolves and subsidizes the future. It doesn't just shift; it provides the capital to fund R&D and new ventures, allowing them to adapt their monetization to include ads, subscriptions, and usage fees as the market matures.
- Capital & Compute Intensity: Beyond data, these incumbents possess a near-unassailable advantage in capital and compute infrastructure. Training and serving state-of-the-art models at a global scale requires billions of dollars in specialized hardware, including custom-designed silicon like Google's TPUs. This creates a massive capital barrier, ensuring that only the best-funded players can compete at the frontier of AI development, further solidifying their market position.
- Unassailable Distribution: Their AI products can be bundled and set as the default within their own ecosystems (Android, Windows, Chrome, Office 365). This provides a zero-cost path to billions of users, an overwhelming advantage that neutralizes the threat from any challenger with a technically superior or better-priced product but no equivalent distribution.
This creates a moat that’s as much economic as technical. Without the index, any synthesis engine risks becoming a parrot whispering from stale data. By integrating their own AI, these incumbents ensure they remain both the library and the librarian.
The real question isn’t whether AI will replace search. It’s whether any company without a top-tier index can truly compete against these integrated giants.
Yet this moat exists under the shadow of regulation. Antitrust in the US and EU could force unbundling of index and synthesizer. New laws like the EU AI Act may reshape data use and impose compliance moats of their own. Regulation could alter the very dynamics that protect incumbents today.
Amazon, TikTok, YouTube, Apple, and OpenAI reshape discovery, but none maintain a global-purpose index. They dominate verticals or synthesis, not indexing. The competitive moat is owning both shelves and summaries. today, in Western general-purpose search at global scale, Google and Microsoft are the main players operating at true global scale with both shelves and summaries. In other regions and verticals, we already see credible exceptions, from Baidu in China to vertical search platforms in travel, commerce, and enterprise data ecosystems. But the central paradox holds: the synthesis layer only thrives when it is tethered to a live, industrial-scale index.

The Risks of an AI‑Only World
Before you celebrate, let’s be clear: relying too much on synthesis engines has risks.
- Hallucinations: AI can invent sources or facts. Trust is fragile when accuracy is optional.
- Bias: Filtering is opinionated. You don’t see what’s hidden, only what’s served.
- Narrowed discovery: Instead of exploring page after page, you get one narrative. Convenient, yes. But it quietly reduces perspective.
- Over‑dependence: If synthesis engines rely on search engines for source material, and search engines weaken economically, the entire ecosystem suffers.
- Privacy: Centralized synthesis funnels sensitive queries into a few vendor logs, enlarging the surveillance surface.
It’s like asking one friend for every book summary you ever read. Handy, until you realize you’re only getting one person’s interpretation.
Compensation Mechanics and Freshness
If AI overviews reduce publisher clicks, new compensation models become critical to sustain content freshness. Licensing agreements, pay-per-crawl schemes, and revenue-sharing frameworks could give publishers direct incentives to keep producing high-quality information even if referral traffic declines.
Cloudflare’s newly announced “pay-per-crawl” service is an early signal of how the web’s economics may rebalance, turning crawling and indexing into monetized services rather than free extraction.
The long-term sustainability of synthesis-first search will likely hinge on whether these models scale, ensuring a continuous supply of fresh, reliable content.
What It Means for Product Leaders
Here’s what actually matters if you’re building products.
- Search engines: Double down on completeness, freshness, and transparency. Don’t compete with AI on summaries. Beat it on trust.
- AI tools: Embrace your role as the synthesis layer. But make provenance visible, or risk losing credibility fast.
- Vertical players: Assume multi‑step journeys will collapse into a single conversational interaction. If your value chain relies on browsing, prepare to be compressed.
- Everyone: Design for a hybrid user. They want efficiency sometimes, agency always, and trust everywhere.
A Special Note for Enterprise Leaders
While this article's focus is the future of public web search, the core tension between indexing and synthesis provides a powerful analogy for the challenges within a corporate environment.
In a corporate environment, the stakes are even higher. An AI that only synthesizes your company's internal data risks creating confident-sounding summaries that lack crucial context.
This challenge is amplified because internal data is a complex mix of structured data (like financial records) and unstructured data (like contracts and emails).
Furthermore, all of this internal information operates under strict data governance, security, and residency requirements. For an enterprise, an AI's answer must therefore be more than just factually correct; it must be fully compliant, ensuring that sensitive information is never surfaced or transferred in a way that violates policy.
True enterprise intelligence requires a hybrid model that can both summarize and provide a clear, trustworthy path back to the original source document. This process of connecting AI-generated answers to verifiable facts is known as grounding, and it is the core challenge of business process intelligence in the age of AI.
This highlights the crucial difference between consumer-grade synthesis and enterprise-grade intelligence. A consumer asks what the best sneaker is. An enterprise leader needs to know why a 'procure-to-pay' process is inefficient. The 'why' is not a single fact but a sequence of events buried in data.
A synthesis engine can flag the inefficiency, but leaders need the root cause: Is it a bottleneck in approvals? Is a specific supplier consistently late? Only a system grounded in the indexed source data (the actual invoices, purchase orders, and communication logs) can provide that verifiable 'why'.
Without that link back to the indexed reality of how work happens, a synthesis is just an interesting opinion; with it, it becomes a powerful tool for genuine business transformation.
The Takeaway
The question isn’t whether AI will kill search. It’s how search will absorb AI without losing what makes it valuable.
Search as we know it won’t disappear. It will evolve into a hybrid model where discovery and synthesis live side by side.
The future belongs to systems that can do both:
- Index and surface the web in full, with freshness, transparency, and user agency intact.
- Synthesize and contextualize answers, collapsing multi‑step tasks into a single interaction.
That’s not death. That’s transformation. And the real winners will be the products that deliver both with trust, speed, and clarity.
So, where does this leave us? Not at the funeral of search, but at the inauguration of a new, hybrid reality. The future of information isn't a choice between the raw, sprawling shelves of the library and the convenient, eloquent summary from the parrot. It's a fluid dance between the two.
We are entering an era where discovery and synthesis must coexist. Users will demand the efficiency of a single, synthesized answer for low-stakes queries, but they will, and must, reserve the right to walk the aisles themselves, to pull the original books from the shelves when truth, transparency, and trust are on the line.
The challenge for us as product leaders and builders is no longer about picking a winner. It is about designing a better reading room. Our mandate is to architect systems where the path from the summary back to the source is not just visible, but immediate and intuitive. We must build experiences that offer the shortcut without sacrificing the journey, that provide the answer while honoring the evidence.
Because a parrot that can't show you the book it learned from is just telling stories. And a library that no one visits will eventually fall silent. The real innovation won't be in making the parrot smarter, but in ensuring the library never closes.
Probably Asked Questions (PAQs)
Why can’t AI models just crawl the web continuously like search engines do?
Because of cost and legality. Running crawlers at Google’s scale requires billions in infrastructure every year. On top of that, copyright and data ownership disputes make unrestricted crawling risky. Most AI systems instead rely on static snapshots or limited retrieval, not continuous global indexing.
How will monetization shape the balance between indexing and synthesis?
Search indexes are funded by ads. Without ad clicks, the incentive to crawl and update billions of pages daily disappears. That’s why Google is testing ads directly inside AI Overviews. The ability to integrate monetization into synthesis will decide which models remain viable.
Who are the real winners in this shift?
The players that control both a live index and a synthesis engine. Today, that’s mainly Google, with Microsoft as the next strongest contender. Others will need to license indexes, specialize in niches, or risk long-term irrelevance.
What happens if indexing systems weaken economically?
Then synthesis engines suffer too. Without robust indexes feeding them, AI systems risk becoming parrots trained on stale data. This is the paradox: the more synthesis draws clicks away from search, the more it undermines the freshness it depends on.
How does this affect vertical players like ecommerce, travel, and local services?
These sectors are the most exposed. AI excels at collapsing structured, repetitive tasks such as price comparisons, bookings, and local service recommendations. Platforms relying on multi-tab browsing or ad-driven traffic will need to adapt quickly, or risk losing relevance.
What should product leaders do right now?
Design for a hybrid model. Provide unmediated discovery when users need transparency and provenance, and synthesis when they need speed and convenience. The strongest products will allow users to move fluidly between both modes.
You're underestimating the pace of innovation.
The future isn't a monolithic index, but decentralized architectures combining federated data, peer-to-peer protocols, and real-time synthesis that will make your cost-of-crawling argument obsolete.
It’s fair to say AI retrieval is improving fast. Real-time browsing, vector databases, and RAG look like they could erase the freshness gap. But even the best RAG pipeline still relies on someone else maintaining a comprehensive index. Without that substrate, “retrieval” just means fetching from a limited set of sources. The bottleneck isn’t the synthesis layer. It’s the cost and legality of maintaining a global index in real time.
That's a fair point on the pace of architectural innovation, which moves beyond simple crawling. However, the core challenge shifts from being purely economic and legal to one of scale, coherence, and trust. While a decentralized model is theoretically powerful, no such effort has come close to solving the logistical challenge of delivering a consistently fresh, comprehensive, and trustworthy map of the global web. The existing incumbents' advantage isn't just the cost of their infrastructure, but the decade-plus of data on user intent and quality signals used to rank results, a trust and relevance layer that is exceptionally difficult for a fragmented, decentralized system to replicate. My argument is that the integrated, hybrid model remains the most practical and defensible path forward for that reason.
New, non-ad-based monetization models will emerge for pure synthesis engines, freeing them from dependency on search's economic model.
I agree that new monetization models will emerge. However, my point is that the cost of acquiring and refreshing high-quality, global-scale data does not disappear. Whatever the model (subscriptions, usage fees, etc.) it must be robust enough to fund the massive infrastructure that keeps the data fresh. The existing ad model already does this, and as the article notes, it's already adapting by embedding ads into AI summaries, suggesting an evolution, not a replacement.
Another pushback is that synthesis engines will unlock new business models (subscriptions, usage-based pricing, transaction fees) that make them independent from search’s ad economy. Maybe. But the fundamental cost doesn’t go away. Keeping billions of pages fresh costs a massive, ongoing amount per year. Any new model has to match or exceed what ads already fund today. Ads may evolve into blended formats (as Google is already testing in AI Overviews), but they remain the most proven way to subsidize freshness at scale.
This sounds like an argument from someone invested in the current system.
You're defending the 'old' way of doing things (indexing) because the disruption is too radical.
Actually, my thesis argues the opposite. I'm not defending the old system; I'm predicting that the biggest incumbents, like Google and Microsoft, are in the strongest position to lead this transformation precisely because they control both the index and a state-of-the-art synthesis engine. The argument is that AI makes the owner of the largest index stronger, not weaker, by allowing them to create an unbeatable hybrid product. This is a forward-looking analysis of competitive moats, not a defense of the past.
You're focused on the corporate duopoly of Google and Microsoft. What if a decentralized, open-source community builds a competing index and AI model, funded by a foundation or tokenomics, that provides a transparent, non-corporate alternative?
This is a fantastic point and highlights a philosophical divide in the tech world. While open-source AI models are advancing rapidly, building and continuously maintaining a fresh, global-scale web index is a monumental logistical and financial challenge. The infrastructure costs billions annually. To date, no decentralized effort has come close to matching the scale, speed, and freshness of the incumbents' indexes. An open-source synthesizer is plausible, but an open-source index to rival Google's remains, for now, a theoretical challenge more than an imminent market threat.
Some argue decentralized architectures (peer-to-peer crawlers, federated indexes, tokenomics-funded models) will disrupt the incumbents. These are fascinating experiments, but so far none have solved the logistical challenge of freshness and trust at global scale. Crawling the live web is only half the problem. The other half is decades of user intent data, click feedback, and quality signals that teach an index what’s relevant. Infrastructure can be replicated with enough money. Trust cannot.