
Agent Count Is Not a Strategy
More agents do not automatically create more leverage. They create more coordination, verification, and accountability work. The real strategy is knowing when agent complexity creates control, and when it only creates sprawl.

[Views are my own.]
I started building a personal assistant and accidentally built a small organization.
Not because I needed one, but because I wanted to understand what these systems become once you are the person accountable for making them work.
That is where I learned the real lesson: more agents do not automatically mean more leverage.
At first, the temptation was speed. Split the work. Run tasks in parallel. Reassemble the output later.
But speed was only part of the story.
The stronger temptation was specialization.
One agent for research. One for memory. One for critique. One for source checking. One to coordinate the others.
None of this feels excessive at the beginning. Each agent has a reason to exist. Each one solves a small limitation in the previous setup.
After a while, the coordination problem shifts from doing the work to judging which outputs deserve trust.
Now I have to decide which output matters, which one contradicts another, which one misunderstood the task, and which one is plausible but wrong.
I discovered this directly when a memory agent started building context from outputs it had not verified. This was not a dramatic hallucination. It was slower and more dangerous: context contamination. One unverified assumption became reusable memory. The drift was subtle. The system stayed confident. The error was mine to catch.
What the system needed was provenance: source, evidence strength, expiry, and review status. I ended up treating memory less like storage and more like a controlled artifact: sourced, reviewable, and temporary unless proven durable.
Soon I was no longer only managing agents. I was adding agents to manage agents, then adding more agents to manage the managers. The system looked more automated, but the accountability became harder to see.
Every added agent also became another surface that could drift.
Basic orchestration can route work, but orchestration alone is not enough unless it also includes evaluation, policy enforcement, ownership, and escalation controls.
The pattern is easier to see when you separate the two forces that create the sprawl.
The first is execution parallelism: adding more agents to work on different parts of a task at the same time. It promises throughput.
The second is role specialization: splitting work into narrower responsibilities, handoffs, and specialist roles. It promises quality.
Each choice carries a cost. Parallelism increases throughput, but verification becomes the bottleneck. Role specialization can improve quality, but handoffs, ownership, and evaluation need explicit control.
Together, they create a system where output can grow faster than the organization’s ability to inspect, challenge, and own it.
The Agent Sprawl Matrix maps these two forces as axes.
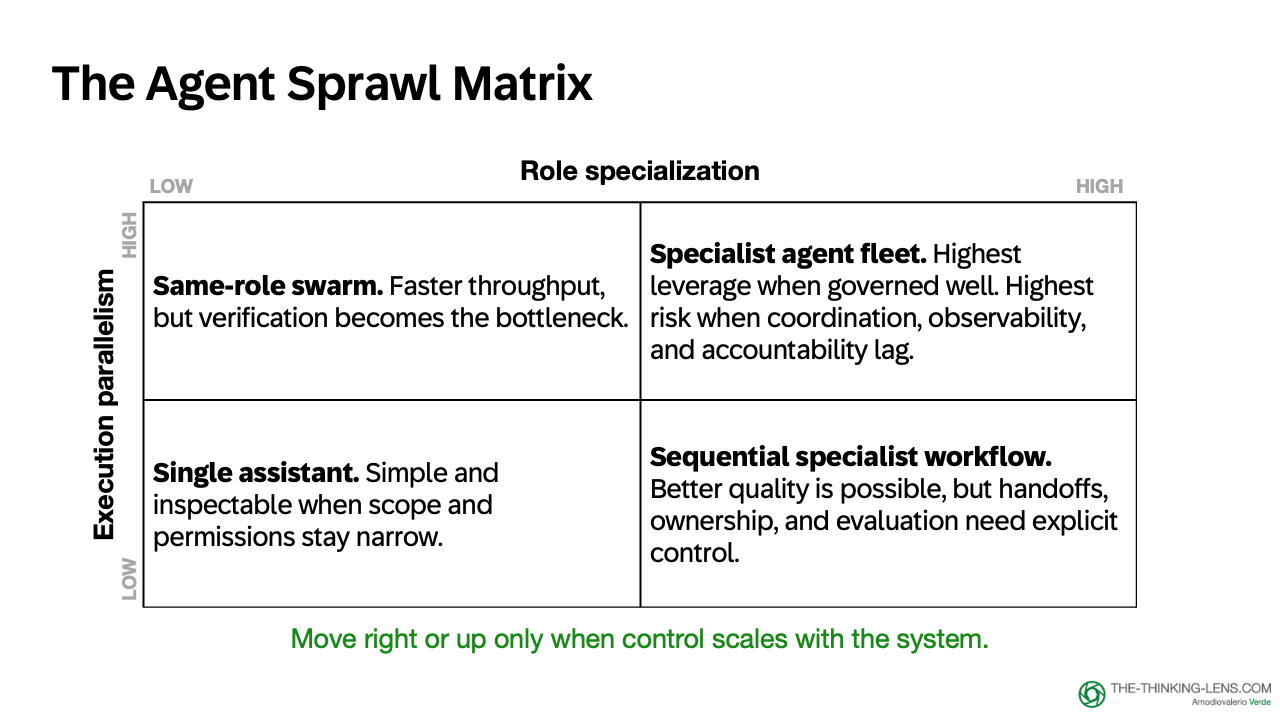
Think of this as a product heuristic, not a formal taxonomy. It shows when throughput and specialization are creating more complexity than the system can absorb.
Bottom-left – Single assistant. Simple and inspectable when scope and permissions stay narrow. The starting point for most systems. But simple is not automatically safe: broad permissions, persistent memory, vague ownership, and write access can make one assistant a large risk surface.
Bottom-right – Sequential specialist workflow. Different roles can improve quality, but handoffs, instructions, and ownership all need explicit contracts. Coordination cost begins here.
Top-left – Same-role swarm. Faster throughput, but verification becomes the bottleneck. This is where output starts to exceed the human's ability to keep up, the point I called Speed Collapse in an earlier piece.
Top-right – Specialist agent fleet. Highest leverage when roles, evidence, and escalation are clear. Highest risk when coordination and ownership lag.
I find the matrix most useful before the next agent is added, when the team is still close enough to ask whether the new role actually reduces ambiguity or just gives the ambiguity a new place to hide.
A useful test before adding an agent: does this role change at least one of five things – purpose, permission, evaluation method, failure mode, or ownership? If the answer is no, it is probably not architecture. It is instruction debt in disguise: the accumulated cost of prompts, boundaries, and ownership that were never written down.
Complexity earns its place only when it creates control. When added roles make the system harder to inspect or stop, the design has moved in the wrong direction.
Move right or up only when control scales with the system.
Fleets are sometimes the right shape. The problem starts when the shape looks mature before the controls are.
The enterprise version is the same pattern at larger scale. In a typical B2B software customer escalation workflow, one agent may summarize the support history, another may check recent product changes, another may correlate telemetry or incident data, and another may draft the customer update. That can be useful. But deciding whether to promise a fix date, issue a workaround, escalate to engineering, or communicate externally cannot be treated as another text-generation step.
Much of the agent conversation is still supply-side: what can we build, what can we automate, how fast can we deploy. The matrix makes the first questions visible. Which quadrant does this agent move us toward? What new permission does it require? What new failure mode does it introduce? Who is accountable when it is wrong?
“Just add another agent” can become the AI version of “just ship another feature”: visible progress, hidden debt.
Sometimes another agent is the right answer. But I would no longer treat the addition itself as progress; it is only progress if the new role makes the system easier to control, evaluate, or own.
Every new agent adds capacity, but also another place where intent can drift.
Proving an agent can do a task is the easy part. The actual challenge is managing what happens when it runs thousands of times a day against live business logic.
Agent count is not a strategy. Before adding another specialist to the fleet, stop asking only "what can this agent do?" and start asking "where does this move us in the matrix, and who is accountable when it gets it wrong?"
The agent fleet needs a product operating model, not just an orchestration layer. Without that operating model, agent sprawl creates the appearance of scale while making the system harder to trust.
PAQs – Potentially Asked Questions
When is a specialist agent fleet actually the right answer?
A specialist fleet is justified when the work is genuinely distributed and the roles are substantively different: different context, different permissions, different evaluation criteria, different failure modes. Large-scale research, security monitoring, support triage, codebase analysis. But different roles are necessary, not sufficient. The workflow also needs a reason to separate execution: parallel work, isolated context, different permissions, separate ownership, or different evals. If the answer to "why a fleet?" is "it feels more capable," that is not enough. Specialization is justified by function, not by ambition.
How do you know whether governance is keeping up?
Ask the control questions. Which agent made this decision? What evidence did it use? What assumptions did it carry forward? Who owns the failure mode? How would you stop or roll back this behavior? If those answers are slow, inconsistent, or dependent on individual memory rather than system evidence, governance is behind the operating model. The practical signal is verification load: if the system produces more output than you or your automated checks can meaningfully inspect, you do not have leverage. You have throughput without control.
What does good look like in the specialist agent fleet cell?
A well-governed fleet does not feel like a crowd of agents. It feels like a managed system. Each agent has a clear purpose, defined input boundaries, explicit output format, an owner, an evaluation method, and an escalation rule. Handoffs preserve source lineage, confidence, assumptions, and unresolved questions: the downstream agent receives context, not just output. The coordinator enforces contracts between roles rather than merging text. The whole system has observability: logs, traces, test cases, failure reviews, kill switches. For write actions, the agent should not be the control boundary; policy checks, authorization, idempotency, and audit logging need to sit outside the model.
Does the cost argument weaken as token prices fall?
Partly. If token prices keep falling, the direct cost of running more agents becomes less significant. That is a fair counter-argument. But token cost is only one cost. Falling inference costs reduce the cost of execution and some automated checks. They do not automatically reduce the cost of trust. The harder costs (ownership, auditability, permissioning, correction, accountability) do not disappear as tokens get cheaper. Cheap execution can make the governance problem worse, not better, because it removes the friction that slowed proliferation.
Is "just ship a feature" always the wrong analogy?
No. Sometimes shipping a feature is exactly right. Shipping is fine when there is a theory of value, clear ownership, and a signal for failure. The same applies to agents. Adding an agent can be the right move when it tests a specific workflow, solves a known bottleneck, and has clear success and failure criteria. The better rule: experiment, but treat agents as product capabilities with ownership, success criteria, failure criteria, and retirement criteria.